解密 Java Class 文件不为人知的秘密
Java 诞生多年,因此在网络上,有关 Java Class 文件格式解析的文章有很多,但他们大多数都是在列举《Java 虚拟机》中定义的格式,通读下来,好像所有的东西都讲清楚了,但是我个人好像并没有看懂,不知道定义的这些东西到底是用来存储什么东西的。本文仍然是在讲《Java 虚拟机》中定义的 Class 文件的格式,但会更多的从一个应用开发者的角度,将字节码文件中定义的字段与原始的 Java 代码信息进行一些关联,让应用开发者能够更好的理解其中的内容。当然,文中也存在部分知识点,不太常用或者我也没有了解清楚的,可能会一笔带过。当然,作为经久不衰的 Java ,其强大之处远不是一篇文章能讲清楚的,文中肯定会有疏漏的地方,如果你对其内容感兴趣,可以有针对性的进行深入研究。当然,本文内容近 1.6 万字,也很枯燥,建议大体浏览一遍即可,无需太过深究,如以后遇到相关问题后,在回来查阅即可。 下面为本文正文内容:
Java 诞生快 20 年,能够一直保持良好的兼容性,其 Class 文件结构的稳定性起到了很重要的作用。在我们现在使用的 Class 文件中,其结构定义绝大部分都是在 1997 年发布的第一版 《Java 虚拟机规范》中就已经定义好了。虽然定义的时间距今已经 20 多年过去, Java 发展经历十多个大版本的迭代 以及无数字小的更新,最开始定义好的各项细节几乎没有出现任何改变。
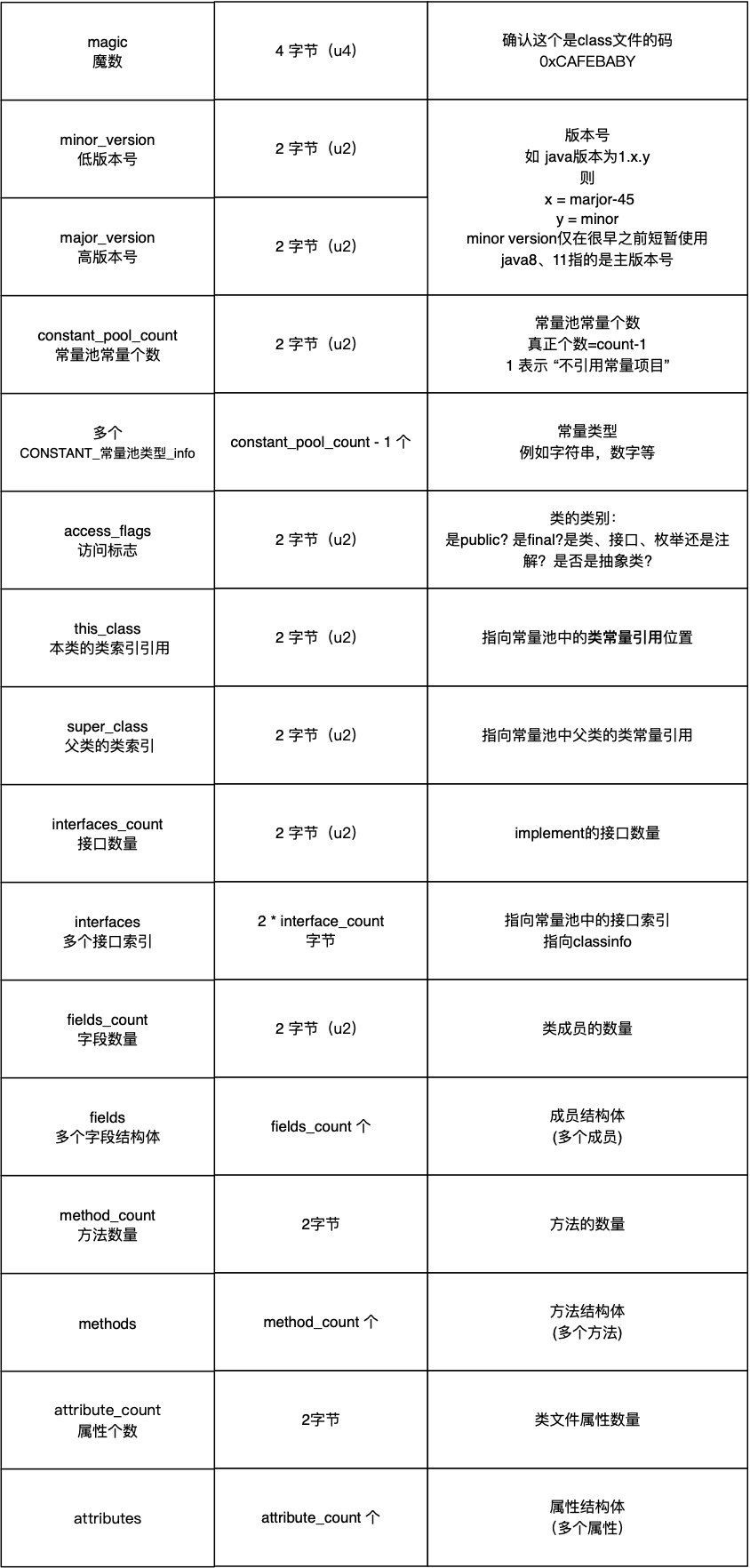
Class 文件是一组以 8 个比特位为基础的二进制流,各个数据项都是按照固定的顺序紧密的排列在一起。先来看下一整体结构,以及每一个字段的长度信息如下:
一、Magic Number 魔数
魔数, 如魔法一样神奇的数字。当我们写代码时,都建议不要使用魔数,因为它在你刚写完代码的时候只有“你和上帝”知道是什么意思,但过一段时间后,就只有“上帝”知道了。而为了区分文件格式,在文件内容的开头,都会使用一些魔数,用于标记和识别文件。如常见的 JPEG 的格式,文件头为 FFD8FF。在 Java 的字节码文件中,其魔数为 CAFEBABE,它是一个4字节的标识符,用于表明该文件是一个 Java 字节码文件。Java 虚拟机可以通过魔数来判断该文件是否为一个有效的 Java 字节码文件,如果不是,则无法被正确加载并执行。
而关于 CAFEBABE 这个魔数的起源,还有一些小故事,Java 创始人 James Gosling 曾透露:
我们以前经常去一个叫
St Michael's Alley餐厅吃饭, 当地传说,美国著名的摇滚乐队Grateful Dead在其大火之前,曾在这里面演出过,可以说这家餐厅就是Grateful Dead的起源之地。在Jerry去世后,他们甚至为建立了一个小型神龛用于纪念。当我们在次来到这家餐厅的时候,发现它已经被改名为Cafe Dead。 我注意到这个名字是 16 进制字符串,而那时我正需要用一对魔数去表示Class文件和Object文件。最终我使用CAFEBDEAD表示了Object文件,与之对应,Class文件头我以CAFE开始,去查找另外 4 个 16 进制字符,并在不经意间发现了BABE,于是我决定使用它们, 因此CAFEBABE成为了Class文件的文件格式。
二、版本号
在 Class 文件中,版本号分为主版本号和次版本号,第 5、6 两位是次版本号,第 7 和第 8 两位是主版本号。主版本号是从 45 开始的,从 JDK 1.1 之后的每一个 JDK 大版本发布,主版本号都会加 1 。
PS: 在 JDK 最早期的版本中,JDK 1.0 ~ 1.1 使用了 45.0 ~ 45.3 的版本号
关于次版本号,曾经在 Java 1.2 之前曾被短暂使用过,但从 Java 1.2 后到 Java 12 之前,次版本号均未使用,全部固定为 0 。而到了 Java 12 后,由于JDK提供的功能集已经非常庞大,有一些复杂的新特性需要以“公测”的形式放出,因此设计者重新启用了副版本号,将它用于标识“技术预览版”功能特性的支持。如果 Class 文件中使用了该版本 JDK 尚未列入正式特性清单中的预览功能,则必须把次版本号标识为 65535,以便Java虚拟机在加载类文件时能够区分出来。
三、常量池
顾名思义,常量池是用来放常量的,但这个常量与我们在 Java 代码中的常量一样吗?这个常量到底包含有哪些信息呢?
在 Class 文件中的常量池里,主要存放两大类常量:字面量(Literal)和符号引用(Symbolic References)。字面量比较接近于Java语言层面的常量概念,如文本字符串、被声明为 final 的常量值等。而符号引用是属于编译原理方面的概念,主要有 类和接口的全限定名、字段的名称和描述符、方法的名称和描述符 等,到目前为止,JDK 中共定义了 17 种不同类型的常量,如下表所示:
| 常量类型 | Tag | Class 文件版本号 |
|---|---|---|
| CONSTANT_Utf8_info | 1 | 45.3 |
| CONSTANT_Integer_info | 3 | 45.3 |
| CONSTANT_Float_info | 4 | 45.3 |
| CONSTANT_Long_info | 5 | 45.3 |
| CONSTANT_Double_info | 6 | 45.3 |
| CONSTANT_Class_info | 7 | 45.3 |
| CONSTANT_String_info | 8 | 45.3 |
| CONSTANT_Fieldref_info | 9 | 45.3 |
| CONSTANT_Methodref_info | 10 | 45.3 |
| CONSTANT_InterfaceMethodref_info | 11 | 45.3 |
| CONSTANT_NameAndType_info | 12 | 45.3 |
| CONSTANT_MethodHandle_info | 15 | 51.0 |
| CONSTANT_MethodType_info | 16 | 51.0 |
| CONSTANT_Dynamic_info | 17 | 55.0 |
| CONSTANT_InvokeDynamic_info | 18 | 51.0 |
| CONSTANT_Module_info | 19 | 53.0 |
| CONSTANT_Package_info | 20 | 53.0 |
为了更好的理解字面量、符号引用,以及他们与 Java 代码的关系,我写以下的一段测试代码,来看看 Java 中哪些数据会被放在 Class 文件的常量池中:
package com.example;
class ClassFormat {
public final int finalVerbose = 1;
public int verbose = 100;
public int verboseV2 = 32768;
public double doubleVerbose = 1;
public double doubleVerboseV2 = 1.1;
public float floatVerbose = 1f;
public float floatVerboseV2 = 1.00001f;
public long longVerbose = 1L;
public long longVerboseV2 = 2L;
public char charVerbose = 'Z';
public String strVerbose = "This is a string.";
public void testMethod() {
}
}
在这段代码中,我们使用了常见的基本数据类型,它们都有各自的初始化值。在执行 Javac 进行编译的过程中,会将代码中的一些值放入常量区,而一另外一些不会。先说结论,上面示例中的代码中,finalVerbose、strVerbose 和以 V2 结尾的变量的初始值都会写入常量池。
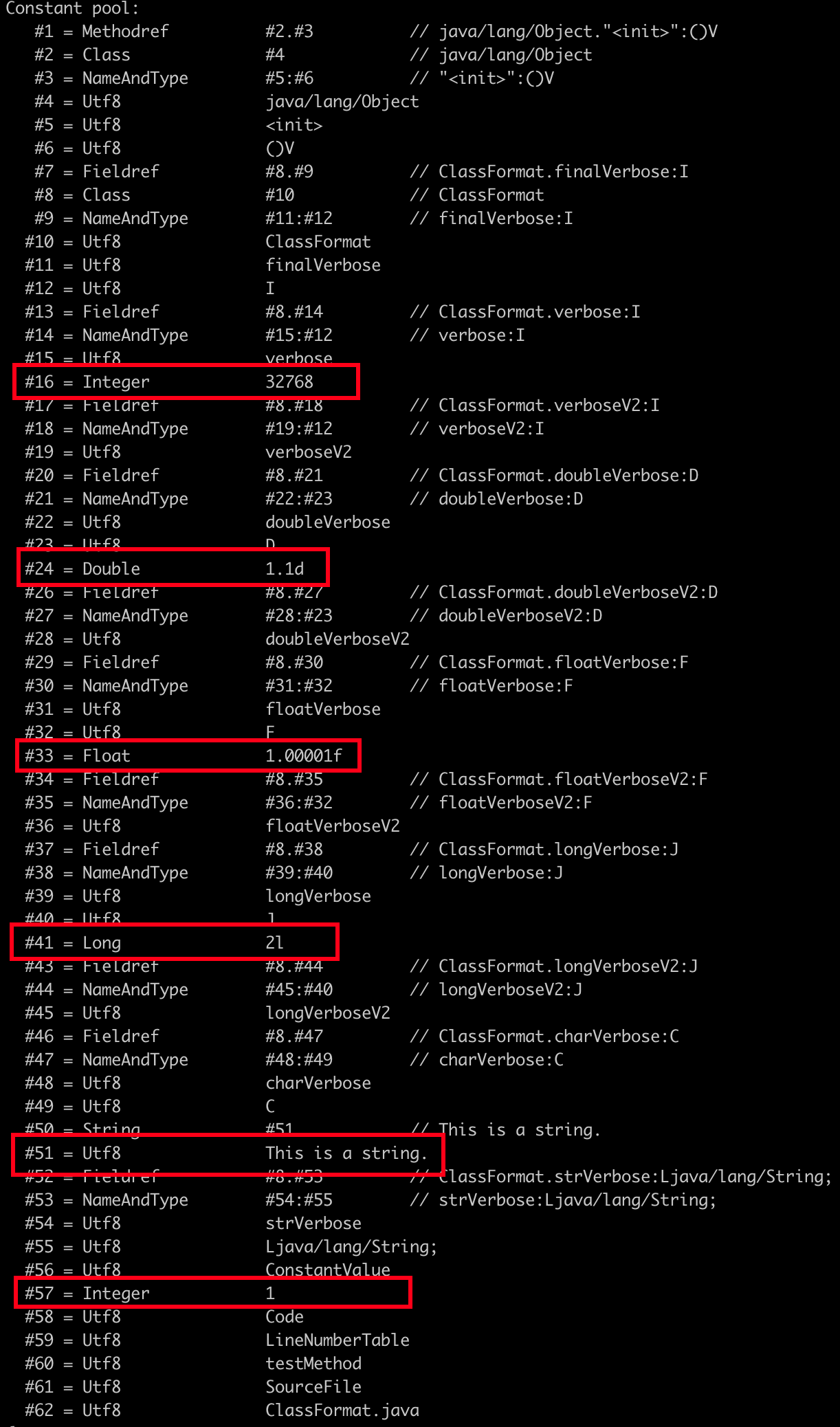
编译后,使用 javap -v ClassFormat 查看常量池,具体内容如上图所示,图中圈出来的是我们在 Java 代码中定义的值,这些需要放在常量池满足以下条件:
- 定义变量时,有 final 修饰的值,如
public final int finalVerbose = 1,此时数字1就会放到常量池中。 - int 型的值范围在
-32768到32767之间的数是不会放入常量池,即两个字节可以表示的整形数字不会放进去,其它都会放进去。 - long / float / double 中除了
0和1以外的其它值都会放出常量池。 - String 中定义的字符串都会放入常量池。
上面这些放入常量池中的字段,是与代码中写的 值 直接相关。除了这些,常量池中还会保存很多符号引用,在上图中还可以看到如下信息:
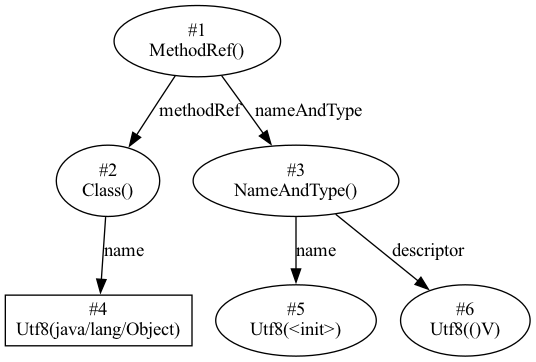
#1 = Methodref #2.#3 // java/lang/Object."<init>":()V
#2 = Class #4 // java/lang/Object
#3 = NameAndType #5:#6 // "<init>":()V
#5 = Utf8 <init>
#6 = Utf8 ()V
#8 = Class #10 // ClassFormat
#10 = Utf8 ClassFormat
#12 = Utf8 I
#17 = Fieldref #8.#18 // ClassFormat.verboseV2:I
#18 = NameAndType #19:#12 // verboseV2:I
#19 = Utf8 verboseV2
其中 #1 表示常量池中的第一个常量,此处为一个 Methodref , 即一个方法的引用,根据 《Java虚拟机规范》中的描述,他有两个字段,分别指向此方法所属的类,和方法的名称和类型描述,此例中为 java.lang.Object 的 <init>() 方法,按其结构绘制图如下:
需要注意的是,我们在类中定义的方法,只有在被调用时,才会生成 Methodref 引用。用于表示方法引用的还有一个常量类型: InterfaceMethodref,此常量用来标记为接口的方法,例如下面代码中的 commonMethod 的调用:
public interface CommonInterface {
public void commonMethod();
}
public class CommonImplementation implements CommonInterface{
@Override
public void commonMethod() {
}
}
class ClassFormat {
CommonInterface common = new CommonImplementation();
public void testMethod() {
common.commonMethod();
}
}
编译后,便会生成一个 InterfaceMethodref,其结构与 Methodref 一致,其指向的类名为 CommonInterface。
与方法对应的便是我们常用的变量,与之不同的是,在代码中定义的类变量以及属性变量,都会生成一个 Fieldref 属性,其结构与 Methodref 一致,此例中的 #17 便是代码中的 public int verboseV2 = 32768;。按其结构绘制图如下:
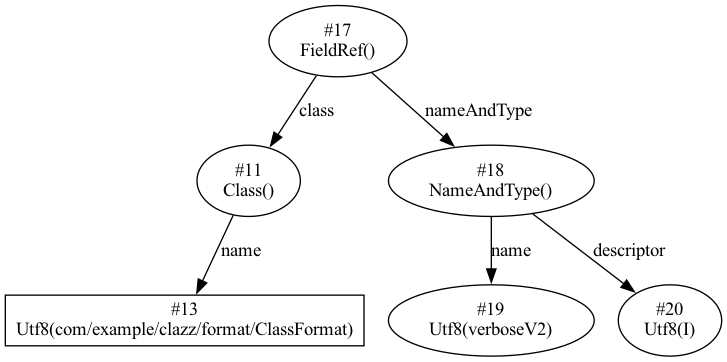
上述常量池中信息除了上述两个字段以外,还有 Class、Utf8 以及 NameAndType, 它们分别用来表示类常量、Utf8 常量以及描述方法/字段名称和类型的常量。
Utf8 常量应该是常量池中使用最多的字段,在代码中定义的 变量名、方法名 都会以该常量的形式将名称存储在常量池中,当在进行 javac 编译时,可添加参数 -g:vars让方法参数名称、局部变量名称也存储在常量池中。
内容到这儿,在 Java 1.2 中定义的 11 个基本常量类型已经完全涉及到了。在后续的 JDK 版本中,随着功能升级,也新增了其它常量。
在 JDK 7 中,添加了 InvokeDynamic 指令,随之添加了三个常量:CONSTANT_MethodHandle_info、CONSTANT_MethodType_info 和 CONSTANT_InvokeDynamic_info。而我们使用的 Java 代码,在 Java SE 1.8 及以上代码才被使用到,其中我们常用的 lambda 就是基于这几条指令实现的,例如下面的代码:
public class LambdaExample {
public void print() {
TestLambdaInterface ii = (i, b) -> i++;
ii.print(10, "");
}
}
interface TestLambdaInterface {
void print(int i, String b);
}
根据这几个常量的结构,可以生成如下关联关系图:
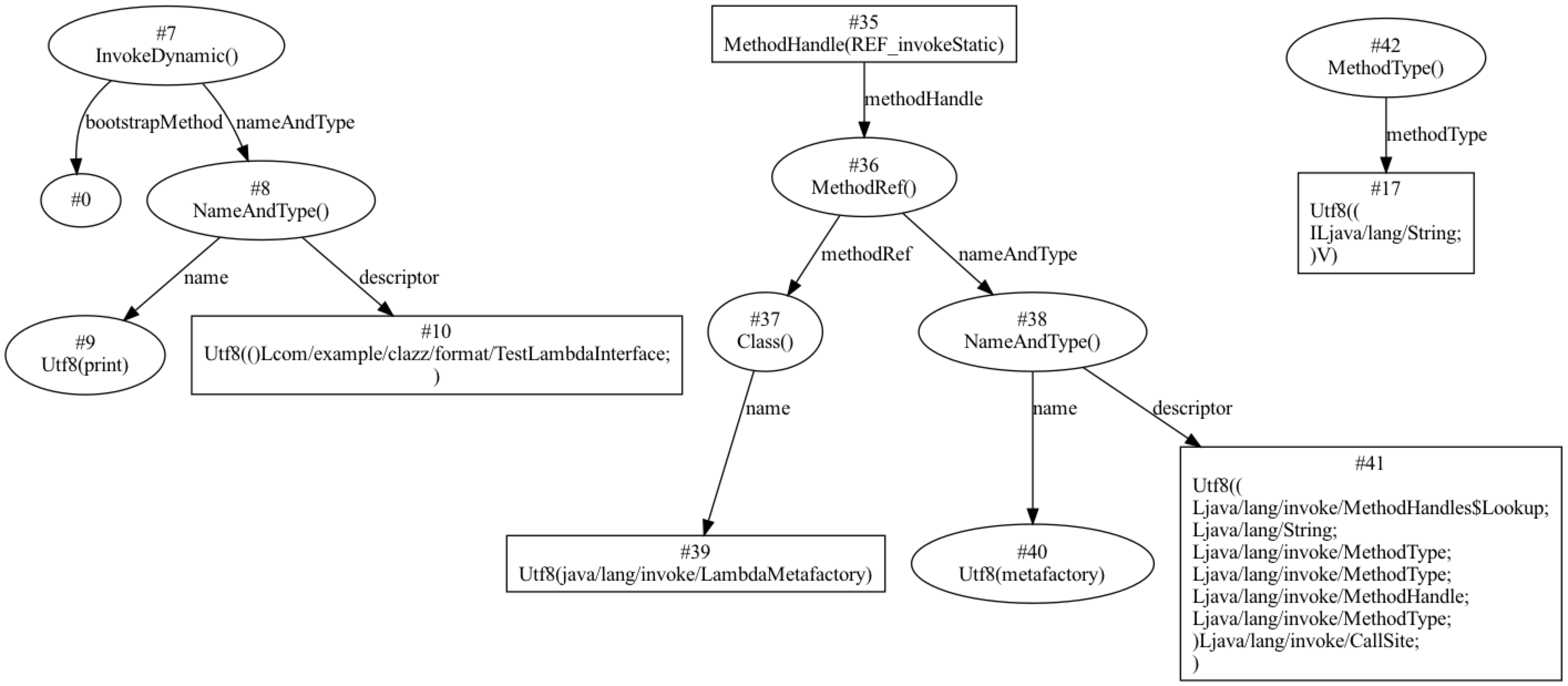
上述代码,在 JVM 中进行执行时,首先会找到常量池中 #7 的常量,通过它指向的 bootstrapMethod ,JVM 会调用这个引导方法,并将参数值传递给引导方法。从而获得一个 CallSite 对象,此对象中包含被真实执行的方法句柄,最终调用到真实的方法。动态调用方法在 Groovy 中使用比较多,有兴趣可使用 Groovy 进行深度研究。此处是用于动态方法调用,与之对应还有动动变量,在 JDK 11 的版本中,添加了 CONSTANT_Dynamic_info,用于实现动态变量的逻辑,但对于 Java 语言, 暂未找到使用此指令实现的逻辑。
在 Java 9 中引入了模块系统,用来组织和管理代码,从而使得应用程序更加安全、可维护和高效。这两个常量分别为 CONSTANT_Module_info 和 CONSTANT_Package_info,分别用来存储模块信息与包信息,并且他们仅能用于 module-info.java 中。先来看以下代码:
// module-info.java
module JavaClassFileStructure {
requires java.base;
requires java.desktop;
exports com.example.clazz;
}
此段代码,编译后会生成 CONSTANT_Module_info 以及 CONSTANT_Package_info,分别用来记录模块信息
JavaClassFileStructure、java.base、java.desktop 和包信息 com/example/clazz 。
以上是现在已有的 17 种常量类型,这里面的这些常量类型,有一部分是原子的,比如 CONSTANT_Utf8_info、CONSTANT_Integer_info,但还有部分,是通过 _index 对象指向其它常量, 如 CONSTANT_Class_info 、CONSTANT_Fieldref_info,在《Java虚拟机规范》中,各常量定义的结构如下:
| 常量类型 | Tag | 字段 |
|---|---|---|
| CONSTANT_Utf8_info | 1 | tag:u1 length:u2 bytes:u1[length] |
| CONSTANT_Integer_info | 3 | tag:u1 bytes:u4 |
| CONSTANT_Float_info | 4 | tag:u1 bytes:u4 |
| CONSTANT_Long_info | 5 | tag:u1 high_bytes:u4 low_bytes:u4 |
| CONSTANT_Double_info | 6 | tag:u1 high_bytes:u4 low_bytes:u4 |
| CONSTANT_Class_info | 7 | tag:u1 name_index:u2 |
| CONSTANT_String_info | 8 | tag:u1 string_index:u2 |
| CONSTANT_Fieldref_info | 9 | tag:u1 class_index:u2 name_and_type_index:u2 |
| CONSTANT_Methodref_info | 10 | tag:u1 class_index:u2 name_and_type_index:u2 |
| CONSTANT_InterfaceMethodref_info | 11 | tag:u1 class_index:u2 name_and_type_index:u2 |
| CONSTANT_NameAndType_info | 12 | tag:u1 name_index:u2 descriptor_index:u2 |
| CONSTANT_MethodHandle_info | 15 | tag:u1 reference_kind:u1 reference_index:u2 |
| CONSTANT_MethodType_info | 16 | tag:u1 descriptor_index:u2 |
| CONSTANT_Dynamic_info | 17 | tag:u1 bootstrap_method_attr_index:u2 name_and_type_index:u2 |
| CONSTANT_InvokeDynamic_info | 18 | tag:u1 bootstrap_method_attr_index:u2 name_and_type_index:u2 |
| CONSTANT_Module_info | 19 | tag:u1 name_index:u2 |
| CONSTANT_Package_info | 20 | tag:u1 name_index:u2 |
传送门, 常量池结构: https://docs.oracle.com/javase/specs/jvms/se14/html/jvms-4.html#jvms-4.4
看到这里,在 Class 文件中定义的常量结构,基本上都了解清楚了。在回到上一层的结构:

常量池是一个表类型的数据项目,常量池中常量的数量也是不固定的,因此在常量池的入口是一个 2 字节数据,代表常量池中常量的数量。在这里需要注意的是,常量的索引是从 index 为 1 开始的。因此,常量池中的常量个数加 1 后为 constant_pool_count。
注:在 Class 文件格式规范制定之时,设计者将第 0 项常量空出来是有特殊考虑的,这样做的目的在于,如果后面某些指向常量池的索引值的数据在特定情况下需要表达”不引用任何一个常量池项目”的含义,可以把索引值设置为 0 来表示。
四、访问标志
在常量池后,紧接着两个字节是用来标识类的访问标识(access_flags),表示这个类的可访问性,如常见的 public 、final 等信息,具体标识位的值及其含义如下:
| 标志名称 | 值 | 解释 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 声明为公共的;可以从包外访问。 |
| ACC_FINAL | 0x0010 | 声明为最终的;不允许有子类。 |
| ACC_SUPER | 0x0020 | 当通过 invokespecial 指令调用超类方法时,对其进行特殊处理。 |
| ACC_INTERFACE | 0x0200 | 是一个接口,而非类。 |
| ACC_ABSTRACT | 0x0400 | 声明为抽象的;不能被实例化。 |
| ACC_SYNTHETIC | 0x1000 | 声明为生成的;在源代码中不存在。 |
| ACC_ANNOTATION | 0x2000 | 声明为注解接口。 |
| ACC_ENUM | 0x4000 | 声明为枚举类。 |
| ACC_MODULE | 0x8000 | 是一个模块,而非类或接口。 |
这些访问标志中, 其中一些字段与 Java 代码中的关键字一致,根据其名字就知道其在什么场景会出现,我在这儿就不做过多介绍。下面来看一下,两个没有出现在平时的代码中的两个关键字:
第一个为 ACC_SYNTHETIC,此字段就是用来标记此类是编译器生成的,没有与之对应的源代码码。
第二个为 ACC_SUPER,它用于解决调用 super 方法时的问题。 在 JDK 1.1 之前, 编译出来的 Class 文件是不包含 ACC_SUPER 字段的,并且 invokespecial 指令在那时的功能与现在不一致。从 JDK 1.1 开始,编译产生的 Class 文件始终都会添加 ACC_SUPPER,在 《Java虚拟机规范》中描述, Java SE 8 及以上版本中,Java 虚拟机认为在每个类文件中都设置了 ACC_SUPER 标志,无论该标志在类文件中的实际值和类文件版本如何。
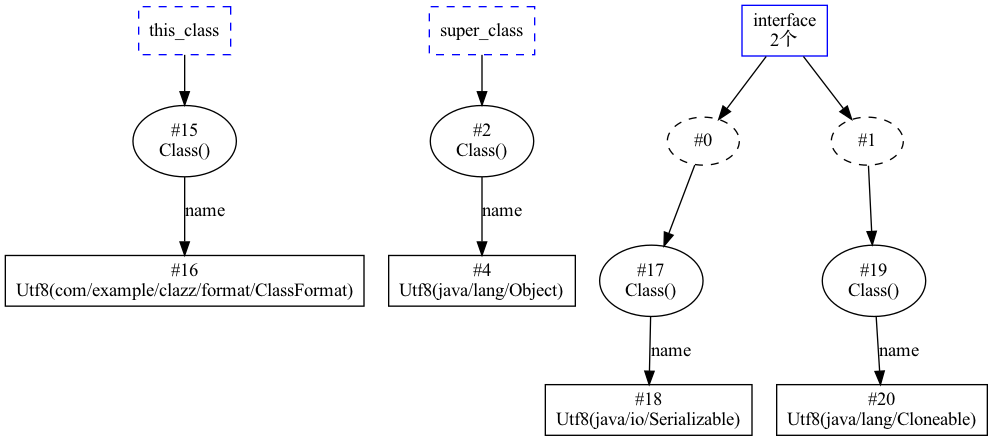
五、 类索引、父类索引、接口索引列表
在 Class 结构中,会分别有两个字节来表示当前类索引(this_class) 和父类索引(super_class),这两个字节分别存储的两个指向常量值的索引。除此之外,Java 中继承的接口可以是多个,因此在 Class 文件中定义了一个与常量池类似的表结构,用于存储所有的接口,需要注意的是, 它的索引是从 0 开始,即 interfaces_count 的值与 interfaces[] 数据中元素个数一致。表结构中存储的每一个接口的信息与 this_class 一样,也是用两个字节来存储指向常量池的索引。比如代码
public class ClassFormat implements Serializable, Cloneable {
}
中的结构如下图所示:
六、字段集合
在使用 Java 语言编写代码时,变量有三种,一种是类级别变量,如 public static int staticVerbose = 1; ,第二种是实例变量,如 public int verbose = 2; ,还有一个是局部变量,如定义在方法代码块中的变量。前两种变量从 Class 文件的角度来看,他们并没有太大的区别 ,变量编译后,编译后都会放到字段集合中进行存储。而局部变量不会放到字段集合中去。与常量池类似,字段集合也是一个表结构,下图为字段的结构表:
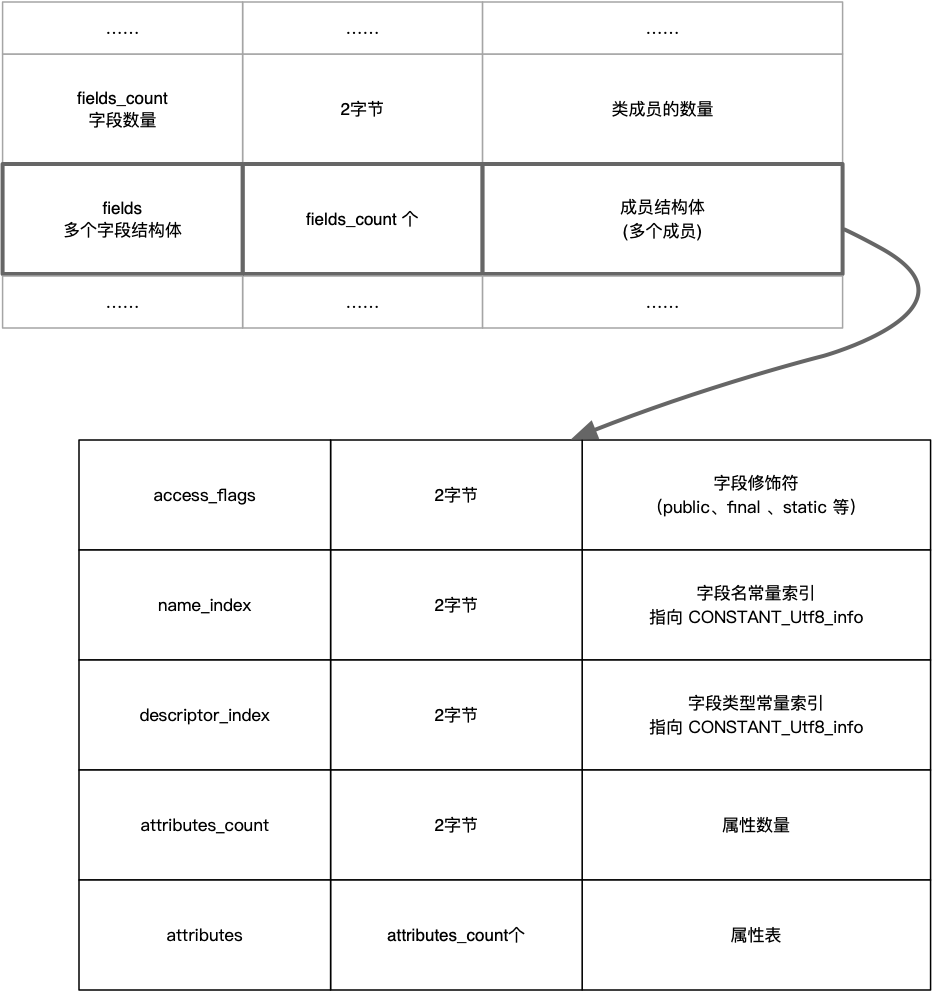
从图中可以看到,每一个字段信息中包含有 5 个字段,属性是一个嵌套的表结构。从上到下,第一个是 access_flags,里面存储着字段修饰符,它与类中的 access_flags 值是非常类似的,都是使用两个字节的数据类型,但他们之间值范围有略微的差别,字段可以设置的标志位和含义如下所示:
| Flag名称 | 值 | 解释 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 声明为公共的;可以从其它包外部访问。 |
| ACC_PRIVATE | 0x0002 | 声明为私有的;只能在定义该类和属于同一个nest(§5.4.4)的其他类中访问。 |
| ACC_PROTECTED | 0x0004 | 声明为受保护的;可以在子类中访问。 |
| ACC_STATIC | 0x0008 | 声明为静态的。 |
| ACC_FINAL | 0x0010 | 声明为final;在对象构造之后不会被直接赋值(JLS §17.5)。 |
| ACC_VOLATILE | 0x0040 | 声明为volatile;不能被缓存。 |
| ACC_TRANSIENT | 0x0080 | 声明为transient;不会被持久化对象管理器写入或读取。 |
| ACC_SYNTHETIC | 0x1000 | 声明为synthetic;不在源代码中存在,编译时生成,如内部类中持有的外部类引用变量 |
| ACC_ENUM | 0x4000 | 声明为枚举的元素。 |
关于这几个标志位中,基本都能根据名称知道其含义。在 Class 文件中的访问标识符里面,我没有找到 ACC_SYNTHETIC 修饰的 Class 示例,但字段中还是可以举个例子。在写代码时,应该都使用过匿名内部类,在匿名内部类中,编译器就会为我们生成一些字段 。举个例子:
class ClassFormat {
int verbose = 1;
public void testMethod() {
TestInterface innerVerbose = new TestInterface() {
@Override
public void testMethodV1() {
System.out.println(verbose);
}
@Override
public void testMethodV2() {
verbose ++;
}
};
}
}
上述代码会生成一个内部类,名叫 ClassFormat$1.class 的文件,而编译器为了解决内部类能访问外部类的信息,实现相互访问,编译器会生成一个变量用于支持这种情况。针对这种情况,我们来看一下,其中生成的类结构信息,如下图所示:
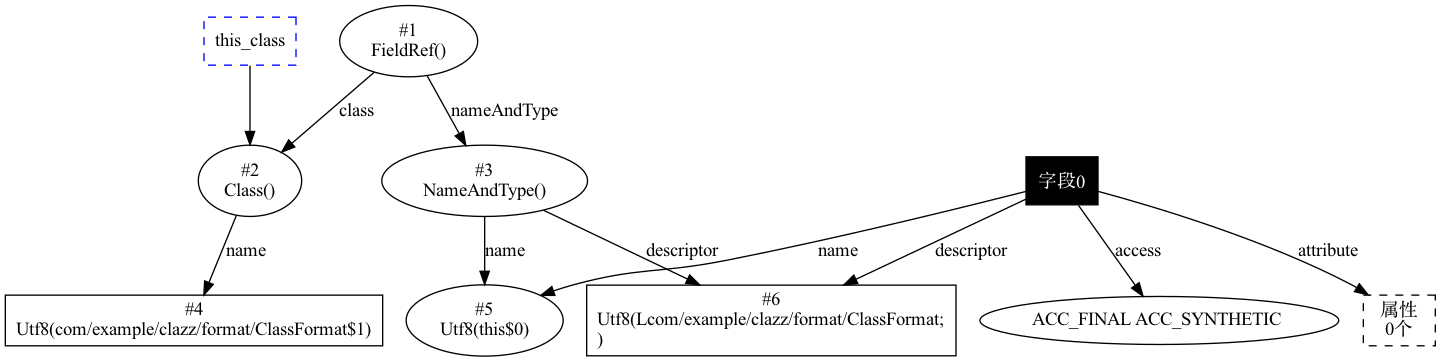
从图中可以看到,在 ClassFormat$1 中有一个名叫 this$0 的字段,类型为 com.example.clazz.format.ClassFormat , 此字段就是由编译器生成,因此其访问标识符中有 ACC_SYNTHETIC 。
在访问标识符后面,紧接着的两个字段分别会 name_index、descriptor_index ,各占两个字节,它们将指向常量池中的字段,上例中,name_index 的值为 5 ,即指向了常量池中第五个常量,其类型为 Utf8 ,存储的值为 this$0,descriptor_index 的值为 6, 类型同样为 Utf8,存储的值为 Lcom/example/clazz/format/classFormat;。
紧随其后的便是字段的属性表数据,属性表是一个非常复杂的结构,并且字段、方法、类都有对应的属性,此处先跳过属性的内容,后文中将进行统一梳理。
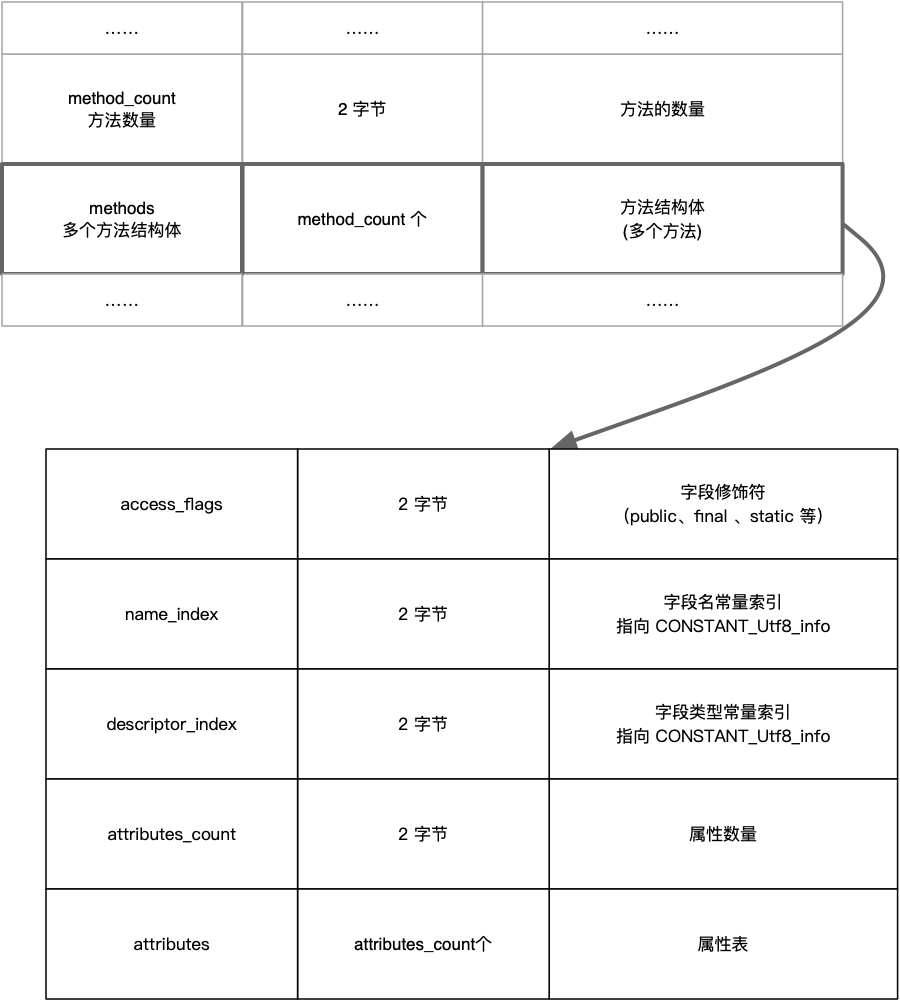
七、方法表
与字段表类似,整个方法字段的结构体与字段结构体一模一样,方法的结构体如下:
虽然结构体中字段定义一样,但其值包含的内容与范围还是有一些区别的,先看 access_flags ,此字段依然是用来定义其访问修饰符的,包含信息如下:
| Flag名称 | 值 | 解释 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 声明为public,可以从包外访问。 |
| ACC_PRIVATE | 0x0002 | 声明为private,只能在定义类和其他属于同一嵌套的类中访问。 |
| ACC_PROTECTED | 0x0004 | 声明为protected,可以在子类中访问。 |
| ACC_STATIC | 0x0008 | 声明为static。 |
| ACC_FINAL | 0x0010 | 声明为final,不能被覆盖。 |
| ACC_SYNCHRONIZED | 0x0020 | 声明为synchronized,方法调用将被封装在一个监视器使用中。 |
| ACC_BRIDGE | 0x0040 | 桥接方法,由编译器生成。 |
| ACC_VARARGS | 0x0080 | 声明具有可变数量的参数。 |
| ACC_NATIVE | 0x0100 | 声明为native,实现使用的是Java编程语言之外的语言。 |
| ACC_ABSTRACT | 0x0400 | 声明为abstract,没有提供实现。 |
| ACC_STRICT | 0x0800 | 声明为strictfp,浮点模式为FP-strict。 |
| ACC_SYNTHETIC | 0x1000 | 声明为synthetic,在源代码中不存在 |
这些修饰符大部分都是常见的,看其名就能知其意,其中 ACC_BRIDGE 以及 ACC_SYNTHETIC 是由编译器生成的,平时基本不会关注到。其中 ACC_BRIDGE 用于范型中,标识该方法为编译器自动生成的桥接方法,用于兼容范型,在这里,先来看一下泛型的示例代码:
interface GenericInterface<T> {
T testBridgeMethod();
}
class ClassFormat implements GenericInterface<String> {
@Override
public String testBridgeMethod() {
return null;
}
}
代码中,testBridgeMethod 返回的是一个泛型,在 ClassFormat 中使用的具体类型为 String,将此代码进行编译,编译后的产物 ClassFormat.class 文件中会生成一个 bridge 的方法,因此编译器会在此方法中加入 ACC_BRIDGE 和 ACC_SYNTHETIC 这两个方法修饰符。最终 ClassFormat.class 方法表结构如下所示:

从结构中可以看到,在 ClassFormat.class 文件中的方法表里面有两个方法,用 Java 代码表示如下所示:
public String testBridgeMethod(){
return null;
}
public Object testBridgeMethod() {
// 此方法即为编译器生成的代理方法
// 通过 invokevirtual 调用方法 testBridgeMethod:()Ljava/lang/String;
// invokevirtual #2 // Method testBridgeMethod:()Ljava/lang/String;
}
上述代码在 Java 中并不合法,Java 中的方法重载时需要方法名相同,却需要拥有一个与原方法不同的特征签名。在 Java 源代码中的特征签名只包含方法名称、参数顺序以及参数类型。而在 Class 文件中,字节码中的特征签名还包含方法返回值以及异常表,因此上述逻辑在 Class 文件中是合法的。
另一个访问标志位 ACC_STRICT 也很少用到,在 java 中有一个关键字 strictfp 与之对应。在虚拟机执行时,浮点运算有两种运行模式:严格浮点模式和非严格浮点模式。当我们执行严格浮点运算时,在所有的Java虚拟机实现上运行结果都是精确相等的。需要注意的是,在 Java 17 及以后,此关键字已经不在使用了。
在访问标识符后面,紧接着的四个字段信息name_index、descriptor_index、attributes_count、attributes 与字段表中的格式一致,在此处就不在赘述。
八、属性表
属性表(attribute_info) 在 Class 文件中用于多处地方,在 Class 文件最末尾是属性表,在字段(field_info)和方法(method_info)里面也都包含属性表。与Class文件中其他的数据项要求严格的顺序、长度和内容不同,属性表中的限制稍微宽松一些,不再要求各个属性表具有严格顺序,并且《Java虚拟机规范》允许只要不与已有属性名重复,任何人实现的编译器都可以向属性表中写入自己定义的属性信息,Java虚拟机运行时会忽略掉它不认识的属性。先来看一下属性字段中定义的结构:
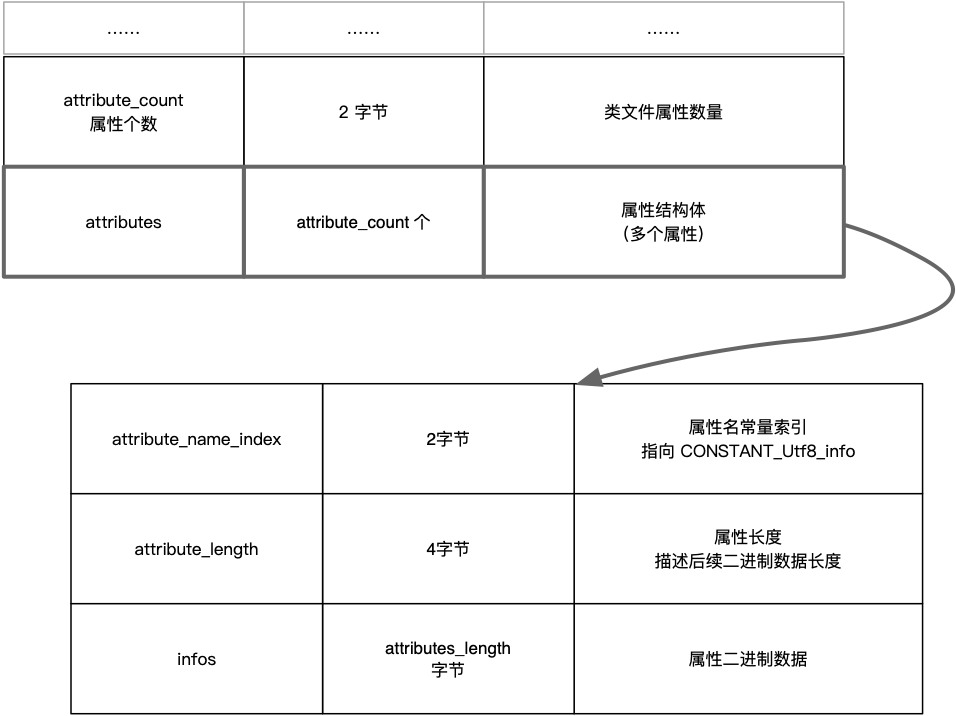
到目前为止,一共定义了 30 个属性,信息如下:
| 属性名 | 版本号 | 位置 | 解释 |
|---|---|---|---|
| ConstantValue | 45.3 | 字段属性中 | 由 final 关键字定义的常量值 |
| Code | 45.3 | 方法属性中 | Java 代码编译后的字节码指令 |
| StackMapTable | 50.0 | Code属性中 | JDK 6 中新增属性,用于类型检查器验证 |
| Exceptions | 45.3 | 方法属性中 | 方法抛出的异常列表 |
| InnerClasses | 45.3 | Class文件属性表结构 | 内部类列表 |
| EnclosingMethod | 49.0 | Class文件属性表结构 | 仅当类为局部类或者匿名内时才会有这个属性,用于标示这个类所在的外围方法 |
| Synthetic | 45.3 | Class文件属性表结构,字段属性中, 方法属性中 | 表示方法、字段是由编译器生成 |
| Signature | 49.0 | 字段属性中, 方法属性中 | JDK 5 中新增,用于支持泛型情况下的方法签名。 |
| SourceFile | 45.3 | Class文件属性表结构 | 记录源文件名称 |
| SourceDebugExtension | 49.0 | Class文件属性表结构 | 源调试信息扩展,如 JSP 文件行号 |
| LineNumberTable | 45.3 | Code属性中 | Java 源代码行号与字节码指令的对应关系 |
| LocalVariableTable | 45.3 | Code属性中 | 方法局部变量表 |
| LocalVariableTypeTable | 49.0 | Code属性中 | 局部变量类型表 |
| Deprecated | 45.3 | Class文件属性表结构,字段属性中, 方法属性中 | 被申明为弃用的方法 |
| RuntimeVisibleAnnotations | 49.0 | Class文件属性表结构,字段属性中, 方法属性中 | 运行时可见注释 |
| RuntimeInvisibleAnnotations | 49.0 | 字段属性中, 方法属性中 | 运行时不可见注释 |
| RuntimeVisibleParameterAnnotations | 49.0 | 方法属性中 | 运行时可见参数注释 |
| RuntimeInvisibleParameterAnnotations | 49.0 | 方法属性中 | 运行时不可见参数注释 |
| RuntimeVisibleTypeAnnotations | 52.0 | 字段属性中, 方法属性中 | 运行时可见类型注释 |
| RuntimeInvisibleTypeAnnotations | 52.0 | 字段属性中, 方法属性中 | 运行时不可见类型注释 |
| AnnotationDefault | 49.0 | 方法属性中 | 记录注解类元素默认值 |
| BootstrapMethods | 51.0 | Class文件属性表结构 | 保存 invokedynamic 指令引用的引导方法限定符 |
| MethodParameters | 52.0 | 方法属性中 | 在 JDK 8 中增加,记录方法名称,可运行时获取 。 |
| Module | 53.0 | Class文件属性表结构 | 记录一个 Module 的名称及相关信息 |
| ModulePackages | 53.0 | Class文件属性表结构 | 记录模块中被 exports 或 opens 的包 |
| ModuleMainClass | 53.0 | Class文件属性表结构 | 记录一个模块的主类 |
| NestHost | 55.0 | Class文件属性表结构 | 用于支持嵌套类的反射和控制的 API ,内部类通过此属性得知自己的宿主类 |
| NestMembers | 55.0 | Class文件属性表结构 | 用于支持嵌套类的反射和控制的 API ,宿主类通过此属性得知自己的内部类 |
| Record | 60.0 | Class文件属性表结构 | 表示当前类是记录类,存储记录组件信息 |
| PermittedSubclasses | 61.0 | Class文件属性表结构 | 属性记录了被授权直接扩展或实现当前类或接口的类和接口。 |
1. ConstantValue
在 Class 文件中的字段里面,可能会包含 ConstantValue ,它是一个固定长度的属性值,其结构如下所示:
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引 |
| attribute_length | 4 字节 | 常量属性的长度, 此处固定为 0x00000010 |
| constantvalue_index | 2 字节 | 常量属性的值的索引 |
在 ClassFormat 中定义两个 final 的字段,代码如下:
class ClassFormat {
public final String CONSTANT_STRING = "constant_string";
public static final String STATIC_CONSTANT_STRING = "static_constant_string";
}
最终生成的字段信息中,会包含一个 ConstantValue 的属性,下图为 STATIC_CONSTANT_STRING 的关联关系图,可以更清晰的看清楚其关系:
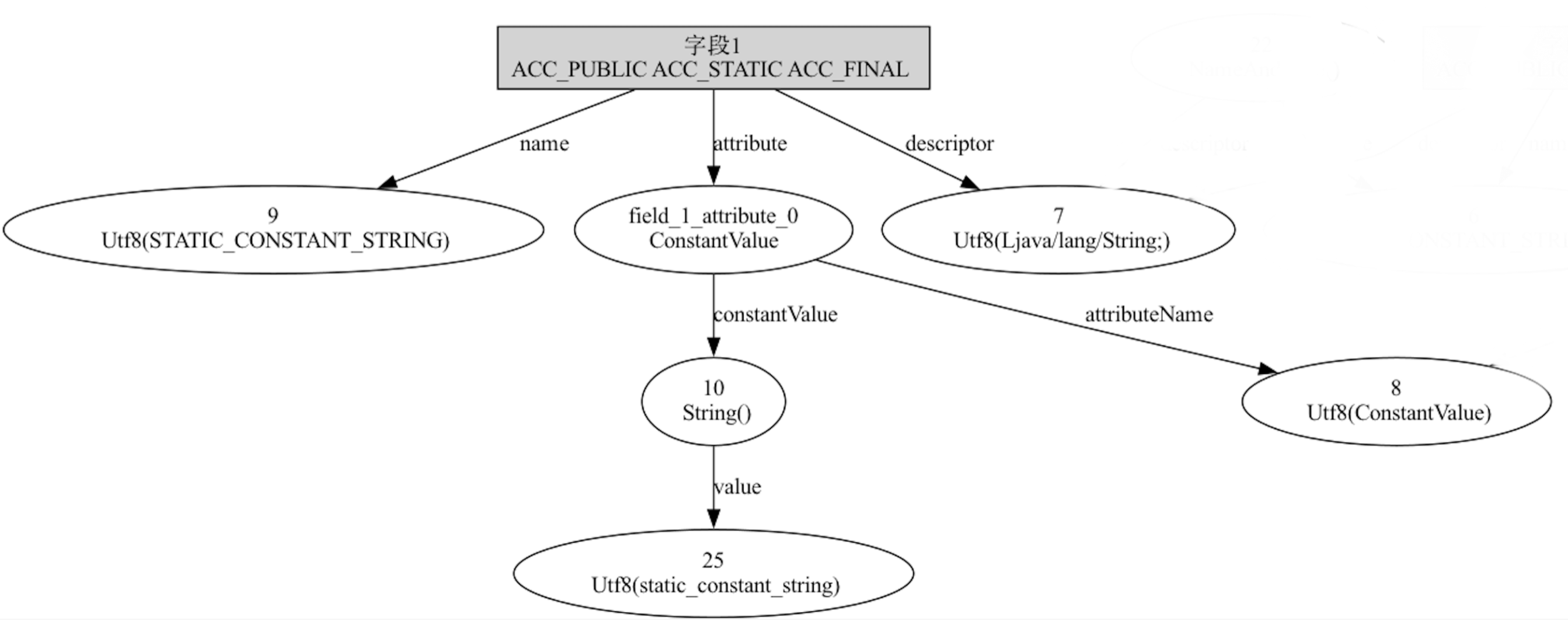
ConstantValue 的作用是通知虚拟机自动为静态变量赋值,对于非静态变量虚拟机会自动忽略此常量值。上例中的 CONSTANT_STRING 与 STATIC_CONSTANT_STRING 都包含有 ConstantValue 的属性,这是 Java 编译器做的事,但《Java虚拟机规范》中仅要求使用 ACC_STATIC 标志的 STATIC_CONSTANT_STRING 中的 ConstantValue 属性。
2. Code
我们编写的 Java 代码中的方法,经过编译器编译后,会生成字节码指令,这此指令会直接存储在 Code 属性中。但是并非所有的方法都会有 Code 属性,如 abstract 修饰的抽象方法就没有 Code 属性。先来看一下 Code 属性的结构:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引,指向 Code |
| attribute_length | 4 字节 | 常量属性的长度, |
| max_stack | 2 字节 | 操作数栈的最大深度 |
| max_locals | 2 字节 | 局部变量表的大小 |
| code_length | 4 字节 | 字节码指令的长度 |
| code | code_length 字节 | 字节码指令序列 |
| exception_table_length | 2 字节 | 异常表的长度 |
| exception_table | exception_table_length 个 | 异常处理表 |
| attributes_count | 2 字节 | 属性表的数量 |
| attributes | attributes_count 个 | 属性表 |
从表中,可以看到 Code 属性中的字段还是比较多的,下面来看一下,其中的一些关键字段:
max_stack字段表示该方法所需的操作数栈的最大深度。在执行该方法时,Java 虚拟机会为该方法分配一个大小为max_stack的操作数栈。当方法调用结束后,该操作数栈会被自动释放。max_locals字段是指该方法所需的局部变量表的大小,当方法被调用时,Java 虚拟机会为该方法分配一个大小为max_locals的局部变量表, 执行期间,会用它来存储方法中的局部变量。局部变量表的大小以变量槽为单位计算,一个变量槽可以存储一个类型为 boolean、byte、char、short、int、float、reference 或 returnAddress 的值。对于类型为 long 或 double 的值,需要使用两个变量槽来存储。方法参数(包括实例方法中的隐藏参数this)、显式异常处理程序的参数(就是try-catch语句中catch块中所定义的异常)、方法体中定义的局部变量都需要依赖局部变量表来存放。但并不是方法体中使用了多少个变量,就会使用多少个变量槽。Java 虚拟机会对局部变量的变量槽进行重用,当代码执行超出一个局部变量的作用域时,这个局部变量所占的变量槽可以被其他局部变量所使用,示例如下:public void testMaxLocals(int indicate, File file) { for (int i = 0; i < indicate; i++) { System.out.println("--"); } File[] listFile = file.listFiles(); System.out.println(listFile); }此段代码的变量槽个数为 4,
for循环中的i在循环执行完后,就会释放掉,后面定义的listFile就会重用这个变量槽。code是一个u1类型的数组,存储着方法执行所需的所有字节码指令序列,字节码指令是一种特殊的机器指令,Java 虚拟机对其进行解释执行。每个字节码指令都具有特定的操作码和操作数。操作码用于指定该指令执行的具体操作,而操作数则用于指定该指令所需的参数。举个例子,代码如下:public class EmptyClass { }对于这样一个空的类, javac 在编译的时候,会为他添加一个默认的构造方法,此方法比较简单,就以他为例,看看
code中都包含哪些信息。按照前面所说的结构,可以解析出来code_length为 5,也就是code块中的内容为 5 byte 。紧接着按位读取,首先读入的指令是0x2a,其助记符为aload_0,此指令的含义是将第 0 个变量槽中为引用类型的本地变量推送到操作数栈顶,在其后无操作数。第二个读入的指令为0xb7,其助记符为invokespecial,此指令的作用是以栈顶的引用类型所指向的对象作为方法的接收者,调用对象的实例构造器方法、私有方法或者是其父类的方法,在其后会有两个字节的index, 指向常量池中类型为CONSTANT_MethodRef的常量,在此处指向的是java.lang.Object的<init>方法。在其后读入的指令是0xb1,其助记符为return,在此处返回值为void。此构造方法生成的的结构图如下: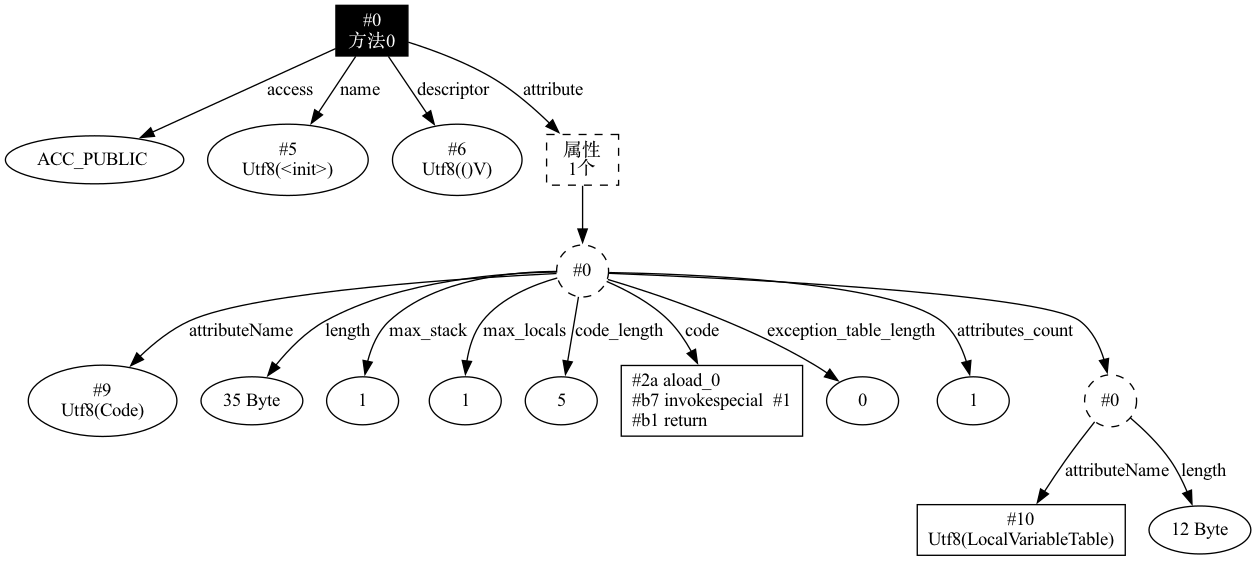
exception_table在字节码指令之后,用于存储此方法的显示异常处理表。异常表并非所有的code字段中都含有,仅代码中有显式处理异常的才会有,即有try{ } catch(Exception e){}的代码。先来看一下它的结构:字段名 数据长度 描述 start_pc 2 字节 字节码 code中的下标,从此条指令开始end_pc 2 字节 字节码 code中的下标,到此条指令前结束handler_pc 2 字节 字节码 code中的下标,当遇到异常时,转到此条指令开始执行catch_type 2 字节 指向常量池中异常类的索引,如果为 0, 代表任意异常 看一段异常表运作的例子, Java 代码如下:
public int setup() { int x; try { x = 1; return x; } catch (Exception e) { x = 2; return x; } finally { x = 3; } }代码很简单,执行逻辑是先执行
try {}中代码块,然后执行finally {}中代码块。虽然上述代码不会出现异常,但假设执行中会出现异常会怎么样?从 java 代码的角度来看,一共以下几种执行路径
try中的代码块正常执行完成,在执行finally中的代码块try代码块中抛出了Exception后,会执行catch中的代码块,仅接着会执行finally中的代码快- 如果执行
catch代码快时,也抛出了异常,会继续执行finally中的代码块 try代码块中执行的代码抛出的异常不是catch中定义的Exception或其子类时,此时会继续执行finally中的代码块
这四条路径,有一条正确的路径以及三条异常路径。在来看一下编译后的字节码指令:
0 iconst_1 # x=1 1 istore_1 # 将1存入变量表[1] 2 iload_1 # 将变量表[1]的值压入栈顶 3 istore_2 # 将1存入变量表[2] 4 iconst_3 # x=3 5 istore_1 # 将3存入变量表[1] 6 iload_2 # 将变量表[2]的值压入栈顶 7 ireturn # 返回 8 astore_2 # 将 Exception 存入变量表[2] 9 iconst_2 # x=2 10 istore_1 # 将2存入变量表[1] 11 iload_1 # 将变量表[1]压入栈顶 12 istore_3 # 将栈顶值存入变量表[3] 13 iconst_3 # x = 3 14 istore_1 # 将3存入变量表[1] 15 iload_3 # 将变量表[3]压入栈顶 16 ireturn # 返回 17 astore 4 # 将其它异常放入变量表[4] 19 iconst_3 # x = 3 20 istore_1 # 将3存入变量表[1] 21 aload 4 # 将变量表[4]中的异常压入栈顶 23 athrow # 抛出异常源码中的 Exception Table 如下:
Exception table: from to target type 0 4 8 Class java/lang/Exception 0 4 17 any 8 13 17 any 17 19 17 any第一条为
try{}代码块抛出异常,且类型为java/lang/Exception或其子类时,去执行catch的逻辑。第二条为
try{}代码块抛出异常,且其类型无法被catch时,会跳转到 17, 即将异常存储到变量表中,然后执行finally的块中的逻辑。第三条为
catch{}代码块中会抛出异常,会跳转到 17, 即将异常存储到变量表中,然后执行finally的块中的逻辑。第四条为将异常存储到变量表中时,出现异常,此时会继续跳转到 17。
3. StackMapTable
StackMapTable 属性是存储在方法表中 Code 属性 里的属性字段里面。它是一个相当复杂的变长属性,在字节码验证阶段,类型检查验证器(Type Checker)会通过 StackMapTable 中的信息,用于确定一段字节码指令是否符合逻辑约束。StackMapTable 的结构如下:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引,指向 StackMapTable |
| attribute_length | 4 字节 | 常量属性的长度 |
| number_of_entries | 2 字节 | 栈帧数量 |
| stack_map_frame | number_of_entries 个 | 栈帧数量 |
此字段从 JDK6 级以上的版本都存在。在 《JVM 虚拟机规范》中,Code 属性 中可以不包含 StackMapTable 属性,虚拟机处理时,如果不包含 StackMapTable 属性,虚拟机会把它当作有一个隐式的 StackMapTable 属性,属性中的number_of_entries 值为 0。
此结构主要是在 javac 以及虚拟机运行时使用,与代码无关,暂无需要过多关注,在此也不过多赘述,并于 stack_map_frame 内的结构信息,如你感兴趣,可以去查阅 《Java 虚拟机规范》。
4. Exceptions
Exception 是在写代码中非常常见的, Exceptions 属性的作用是记录方法中可能抛出的受查异常(Checked Excepitons),也就是在写代码时,throws 关键字后面写的所有异常类型。它的结构见表6-17。
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引,指向 Exceptions |
| attribute_length | 4 字节 | 常量属性的长度 |
| number_of_exceptions | 2 字节 | 表示当前类抛出的异常个数 |
| exception_index_table | number_of_exceptions个 | 指向常量池类的名称 |
此结构比较简单,下面是我创建的内部类的测试代码:
public void config() throws IOException, InterruptedException {
}
编译后,生成的 Exceptions 属性结构如下图所示:
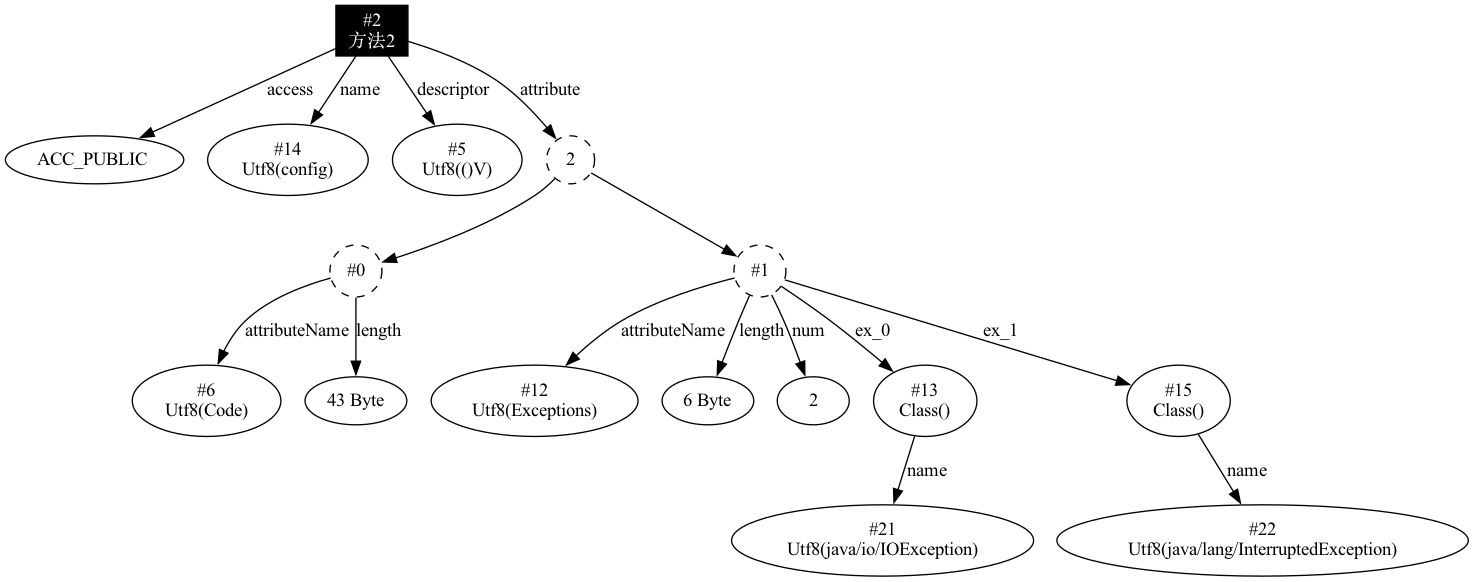
可以看到,在 Exceptions 属性中,有两个元素,分别是 IOException 和 ClassNotFoundException,它们都是对常量池中的 CONSTANT_Class_info 常量的引用。
5. LineNumberTable
LineNumberTable 属性中存储的是 Java 代码中的行号信息,使用它们,可以将Class 文件中的字节码指令与 Java 源文件中的代码关联起来。当我们将 Java 源代码编译成字节码时,每行代码都会被编译成一段二进制字节码指令,并且这些指令在字节码文件中是按照顺序排列的。编译时,编译器会为每个指令记录下它在源代码中的行号,当代码运行时发生异常时,就可以根据行号定位到源代码中出错的地方。下面表格中为 LineNumberTable 属性结构:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 个字节 | 属性名常量池索引,指向值为 LineNumberTable |
| attribute_length | 4 个字节 | 属性长度 |
| line_number_table_length | 2 个字节 | 行号表长度 |
| line_number_table | line_number_table_length * 4 字节 | 行号表信息 |
其中,line_number_table_length 表示行号表的长度,line_number_table 是一个数组,每个元素表示一个字节码指令和它在源代码中对应的行号。每个元素包含了以下两个字段:
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| start_pc | 2 字节 | 指令在字节码中的位置 |
| line_number | 2 字节 | 源代码中的行号 |
下面是一个简单的 Java 示例代码:
package com.example.clazz.format;
public class LineNumberTableExample {
public static void main(String[] args) {
int a = 0;
int b = 1;
System.out.println(a + b);
}
}
编译后,生成的 Class 文件中包含了 LineNumberTable 属性信息,如下所示:
stack=3, locals=3, args_size=1
0: iconst_0
1: istore_1
2: iconst_1
3: istore_2
4: getstatic #7
7: iload_1
8: iload_2
9: iadd
10: invokevirtual #13
13: return
LineNumberTable:
line 6: 0
line 7: 2
line 8: 4
line 9: 13
这意味着,在 main 方法中第 6 行代码int a = 0;对应的字节码指令的位置是 0,第 7 行代码对应的字节码指令的位置是 2,第 4 行代码对应的字节码指令的位置是 4。
这样,当在运行时出现异常时,就可以根据行号表中的信息追溯到源代码中出错的位置了。
6. LocalVariableTable
LocalVariableTable 属性用于描述局部变量表中的变量与 java 源码中定义的变量之前的关系。对于 JVM 虚拟机来说,他并不是必须参数,编译进可使用参数来去掉这项信息。如没有此项信息,在运行调试时,IDE 会使用如 arg0、arg1 等不具有意义的占位符来替代原有的参数名。下面表格为其属性结构:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 个字节 | 属性名常量池索引,指向值为 LocalVariableTable |
| attribute_length | 4 个字节 | 属性长度 |
| local_variable_table_length | 2 个字节 | 局部变量表长度 |
| local_variable_table | local_variable_table_length * 10 字节 | 局部变量表信息 |
其中,local_variable_table_length 表示局部变量表的长度,local_variable_table 是一个数组,其中每个元素表示一个局部变量的信息,包含了以下 5 个字段:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| start_pc | 2 字节 | 字节码中中第一次出现的位置 |
| length | 2 字节 | 代码中出现的长度,及该字段的作用域 |
| name_index | 2 字节 | 局部变量名称在常量池中的索引 |
| descriptor_index | 2 字节 | 局部变量类型在常量池中的索引 |
| index | 2 字节 | 在局部变量表中所在的位置 |
在 JDK 5 引入泛型后,新增了 LocalVeriableTypeTable,此属性与LocalVariableTable 及其相似,只是它用来修饰的是泛型变量,在此处就不在赘述了。
7. InnerClasses
InnerClasses 属性是用来记录内部类与宿主类之间的关联关系的。 当我们在代码中定义内部类的时候,编译器会为当前类以及它的内部类上添加 InnerClasses 属性。

在此结构中, inner_class_info_index 和 outer_class_info_index 指向了常量池中 CONSTANT_Class_info 型常量的索引,分别代表内部类和宿主类。inner_name_index 是指向了内部类名称的索引,为 CONSTANT_Utf8_info 类型。
需要注意的是,outer_class_info_index 在局部类、匿名类中,它的值为 0 。同时,在匿名类中,inner_name_index 也为 0 。
下面是我创建的内部类的测试代码:
public class InnerClassExample {
public class InnerClassDemo {
}
}
编译后,生成的 InnerClasses 属性结构如下图所示:
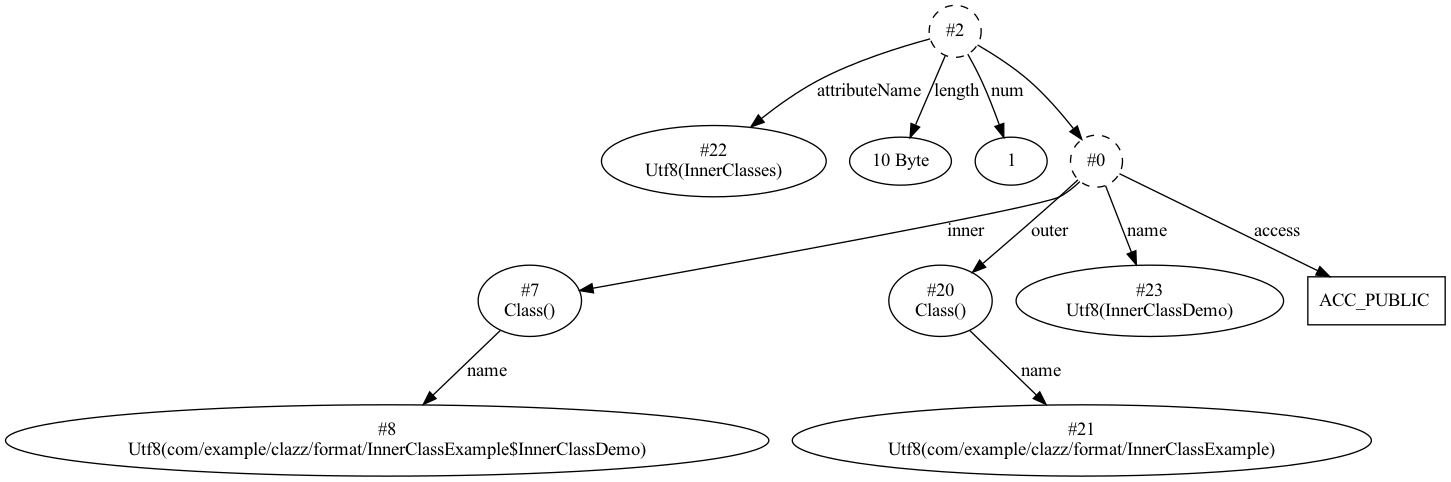
8. EnclosingMethod
EnclosingMethod 属性是在 Class 文件结构的属性块中,他是一个定长的属性。在 Java 中,局部类(LocalClass) 与匿名内部类的 Class 文件中,必须包含 EnclosingMethod 属性值。
匿名内部类是非常常见,但在写代码时,去很少有使用局部类。局部类一种特殊的内部类, 它定义在一个代码块中(如方法、构造函数、初始化块等)而不是类的主体中,它只在该代码块中可见,对于外部代码块是不可见的。 示例如下:
public class EnclosingMethodExample {
public void setup() {
class A {
String a = "10";
}
A a = new A();
System.out.println(a.a);
}
}
在 setup 方法中,定义了 class A , 编译后会生成 EnclosingMethodExample$1A.class 文件。
EnclosingMethod 属性结构也非常的简单,在结构中,包含两个指向外部类和方法的字段,具体结构如下:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引,指向 EnclosingMethod |
| attribute_length | 4 字节 | 常量属性的长度, 此处固定为 0x00000100 |
| class_index | 2 字节 | 类常量索引,指向常量池中 Class 字段 |
| method_index | 2 字节 | 方法常量索引,指向常量池中 MethodRef 字段 |
上述 EnclosingMethodExample$1A.class 文件中,属性字段中的第二个属性(下标为 1 的那个)便是 EnclosingMethod 属性,其关联结构如下图所示:
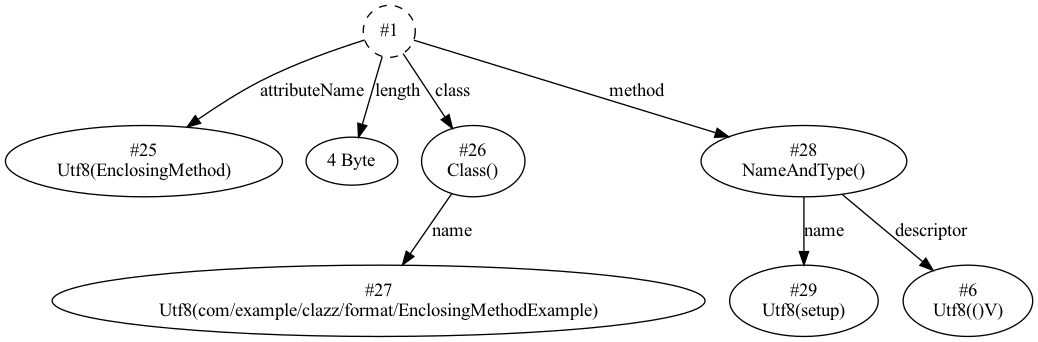
通过属性表,可以看到此局部类在 EnclosinMethodExample.setup 方法中。
9. Synthetic
Synthetic 是用来修饰类、方法、变量,表示它们不是由 Java 源代码直接产生,而是由编译器生成。它是一个标志类型的布尔属性,因此其结构中的 infos 长度为 0 ,因此它的内容总共只有 6 个字节,结构如下:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引, 指向常量池中 Utf8 的常量,其值为 Synthetic |
| attribute_length | 4 字节 | 常量属性的长度, 此处固定为 0x00000000 |
不过在 JDK 5 之后,也可以使用访问标志 ACC_SYNTHETIC 来表示相同的功能。我尝试了 Java 中匿名内部类生成的变量,并没有 Synthetic 属性。
编译器通过生成一些在源代码中不存在的方法、字段甚至是整个类的方式,实现了越权访问(如访问 private 修饰的变量)或其他绕开了语言限制的功能。除了刚提到的匿名内部类,枚举类也是一个非常典型的例子,在编译时,会生 $VALUES 方法,存放所有枚举元素的数组。
下面是我创建的枚举类型的测试代码:
enum TestEnum {
TEST_ENUM_V1,
TEST_ENUM_V2
}
最后生成的类结构图如下所示:

10. Signature
在 Java 1.5 后的版本中, Java 支持了泛型,而这个 Signature 属性就是用来记录类、方法、变量中的类型变量(Type Variable) 或者参与化类型(Parameterized Type)。Signature 是一个固定长度的属性值,结构非常简单,结构如下表:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引,指向值为 Signature |
| attribute_length | 4 字节 | 常量属性的长度, 此处固定为 0x00000010 |
| signature_index | 2 字节 | 签名的常量索引 |
Java 在编译的过程中,会进行泛型擦除,而 Signature 就是用来存储这些被擦除的信息,让虚拟机能够正确处理其类型。在使用的过程中,泛型有两类,一类是自己定义的泛型参数, 如下示例代码中的 T typeVariable,一类是使用已经定义好的泛型类,使用时指定的具体类型,如下示例代码中的 Map<String, Integer> parameterizedType。
public class VerboseSignature<T> {
public T typeVariable;
Map<String, Integer> parameterizedType;
}
最终生成的 Class 文件中的,这两个字段的属性块中,都会有一个 Signature 的结构,其中 typeVariable 的签名信息为 TT; ,另一个为 Ljava/util/Map<Ljava/lang/String;Ljava/lang/Integer;>;,详细信息如下图所示:
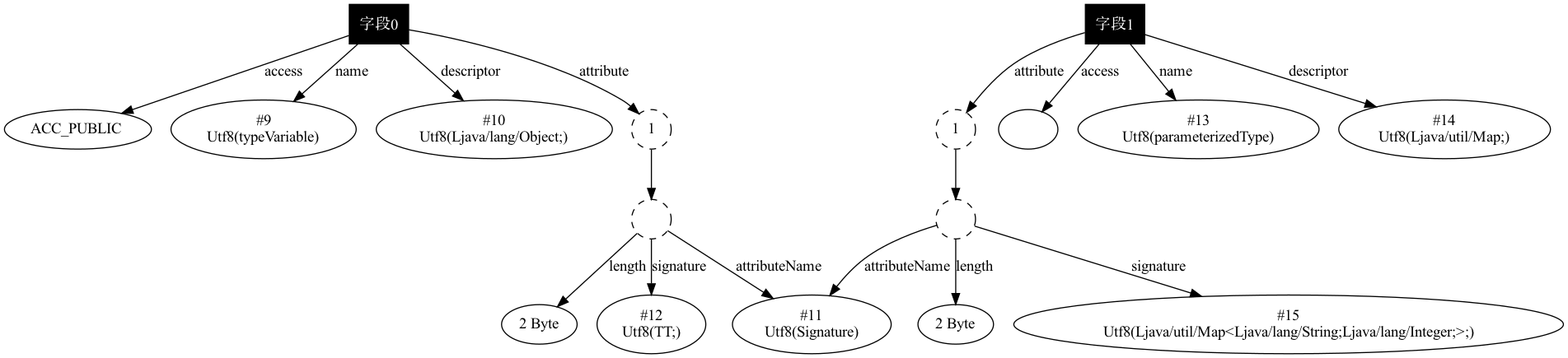
11. SourceFile/SourceDebugExtension
这个属性是用来记录生成 此 Class 文件的源文件名称,此属性的结构是固定长度,结构如下:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引,指向值为 SourceFile |
| attribute_length | 4 字节 | 常量属性的长度, 此处固定为 0x00000010 |
| sourcefile_index | 2 字节 | 源文件名称的常量池索引 |
在使用 Java 的过程中,大部份情况下,类名与文件名是一致的,但是诸如内部类等时会出现例外。此参数对于 Class 文件来说,是一个非必须参数 ,当使用 javac 编译时添加 -g:none 时,生成 Class 文件时,会去掉 SourceFile 等调试信息,可以减少程序体积并提高性能,但是需要注意的时,如果去掉后,出现异常时,不会输出错误代码对应的文件名。最后,下图为 ClassFormat.class 文件中的 SourceFile 属性结构:
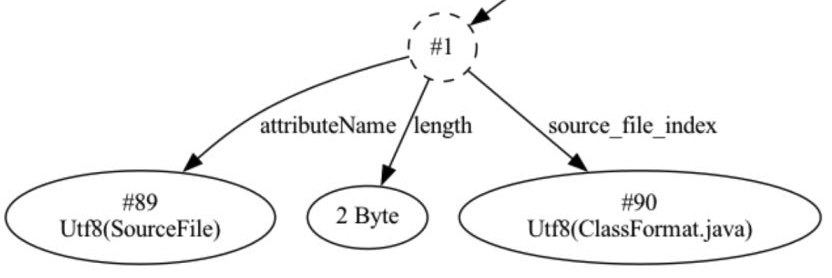
除了 SourceFile 属性,在 JDK 5 时,为了方便在编译器和动态生成的 Class 中加入供程序员使用的自定义内容,新增了 SourceDebugExtension 属性用于存储额外的代码调试信息。典型的场景是在进行 JSP 文件调试时,无法通过 Java 堆栈来定位到 JSP 文件的行号。此时就可以用到 SourceDebugExtension 属性,它的结构如下:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引,指向值为 SourceDebugExtension |
| attribute_length | 4 字节 | 常量属性的长度, 此处固定为 |
| debug_extension | attribute_length字节 | 额外调试信息,整个区域是二进制数据,可以按需进行任意填充 |
12. Deprecated
在写 Java 代码时,使用注解 @Deprecated 标记的类、变量、方法,就会有这个属性值。它是一个标志类型的布尔属性,与 Synthetic 的结构一样,用来表示某个类、字段或者方法已经不在推荐使用。这个属性的存在不会改变类或接口的语义。它的结构如下:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引, 指向常量池中 Utf8 的常量,其值为 Deprecated |
| attribute_length | 4 字节 | 常量属性的长度, 此处固定为 0x00000000 |
13. Annotations
注解,是 Java 中一个非常常用的功能。 注解有几类:
- SOURCE:仅在源码中出现,编译时会被丢掉
- CLASS: 编译后会存储在Class 文件中,但是 JVM 加载时会丢掉,运行时获取不到。注解默认为此行为
- RUNTIME:在 Class 文件中存在, 在运行时 JVM 会加载进来,运行时可获取到
根据定义,可以知道 SOURCE 类型的是无法写入到 Class 文件中的, 而 CLASS 与 RUTIME 的区别是一个可以在运行时使用,一个不可以。在 Class 文件中,也根据这个不同定义了 RuntimeVisibleAnnotations 和 RuntimeInvisibleAnnotations,他们俩的结构一致, 结构相对比较复杂,结构图如下:
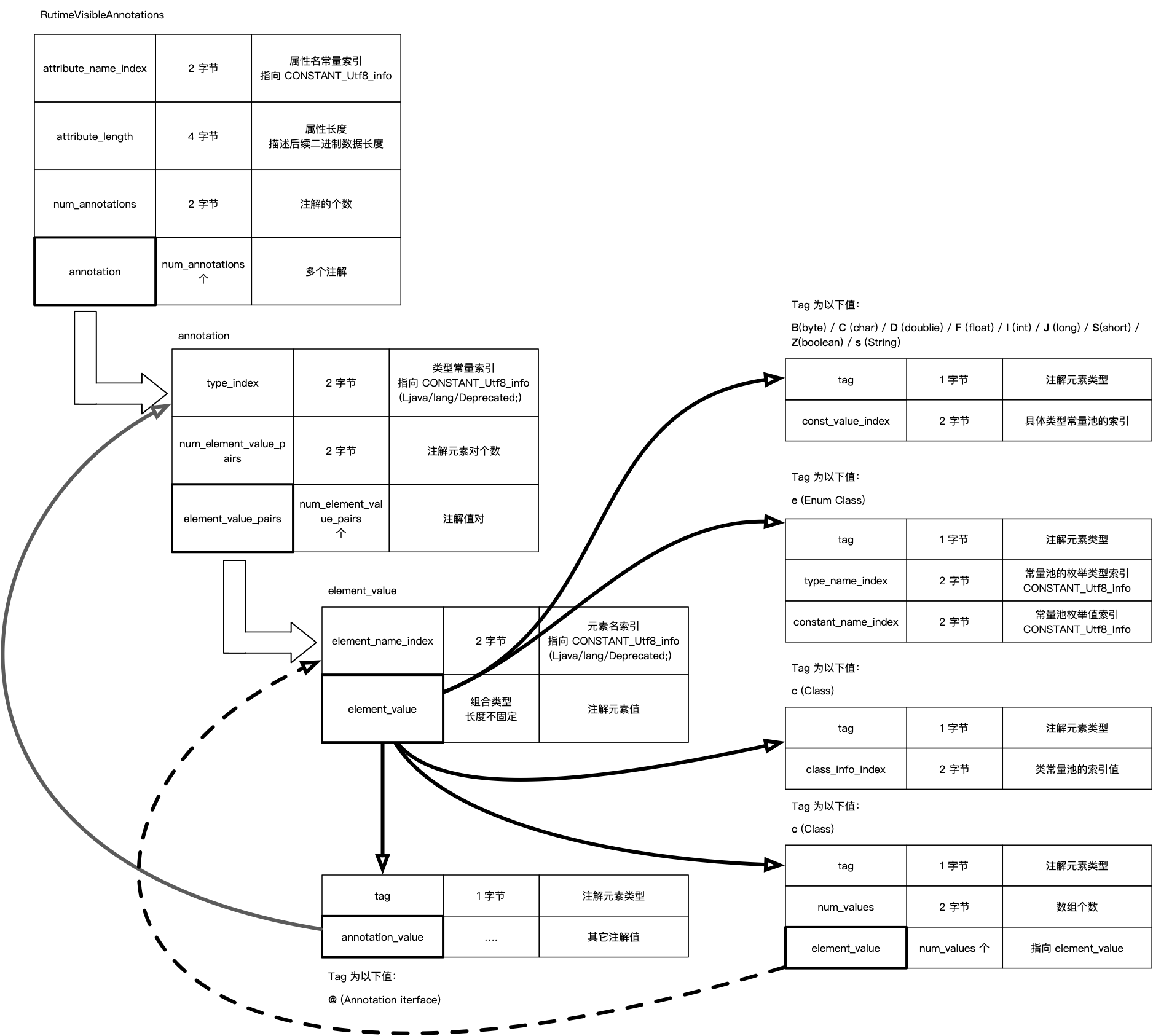
针对这两类注解,attribute_name_index 指向的是值为 RuntimeVisibleAnnotations 或 RuntimeInvisibleAnnotations 的 CONSTANT_Utf8_info 常量值索引。针对 Runtime 的注解,前面刚提到的的 Deprecated 也是是运行时的,但是他并不包含值。除了它,我还定义了一个包含值的运行时注解,代码如下:
@Retention(RUNTIME)
@Target({METHOD, PARAMETER, FIELD, LOCAL_VARIABLE, ANNOTATION_TYPE})
public @interface IntRange {
/**
* Smallest value, inclusive
*/
long from() default Long.MIN_VALUE;
/**
* Largest value, inclusive
*/
long to() default Long.MAX_VALUE;
}
public class VerboseAttributes {
@Deprecated
public int deprecatedVerbose = 1;
@IntRange(from = 1, to = 10)
public int value = 32767;
}
这段代码最终生成的字段属性相关的关系如下图所示:
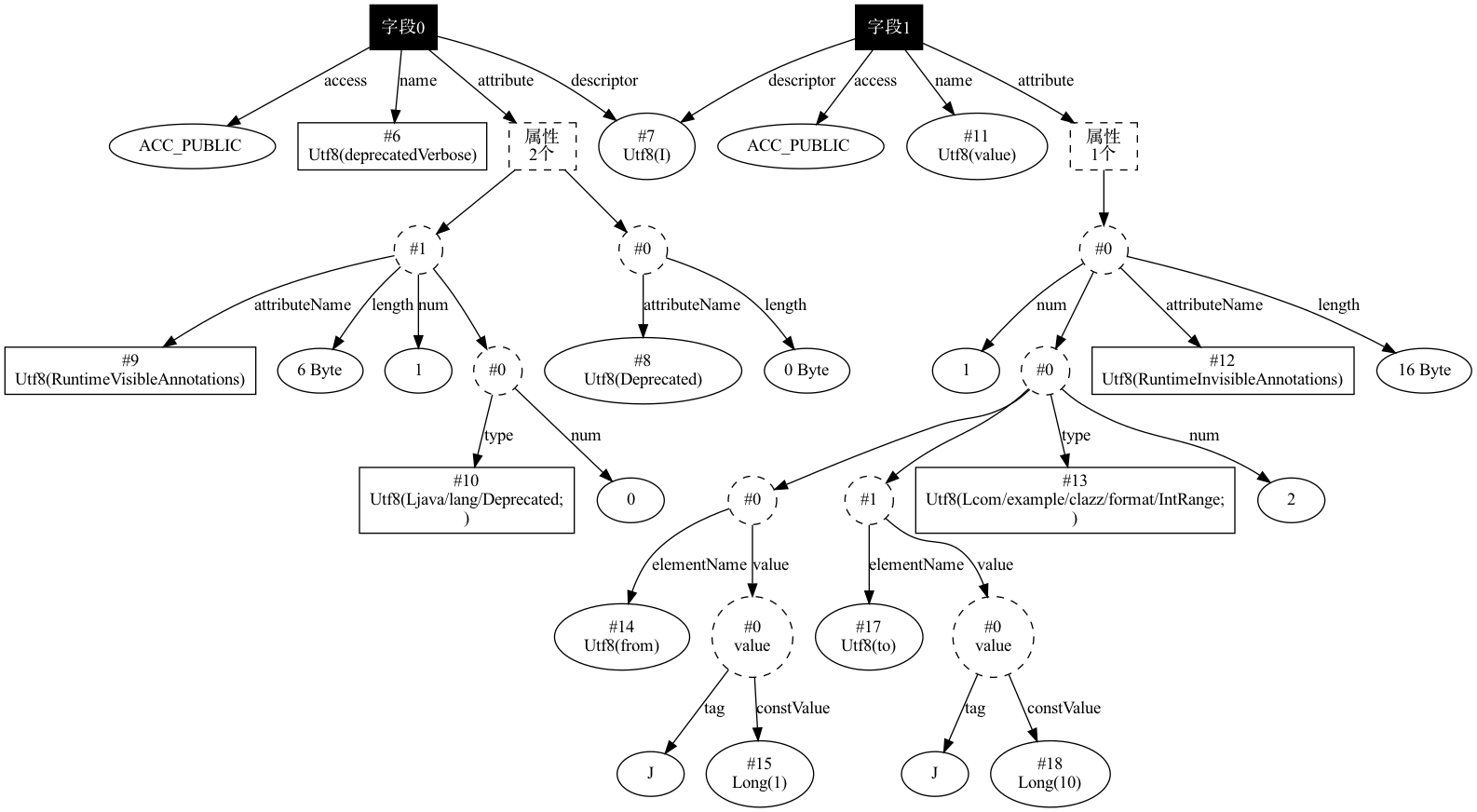
从 Class 结构中的定义中,可以看到,注解里面定义的 Vaule 只能使用常量。终于从底层知道为什么以前写注解的时候,注解值只能为常量了。
14. ParameterAnnotations
在方法中,参数的注解与写到方法上的注解还有一点区别,在《Java虚拟机规范》里面还定义了另外两个 RuntimeVisibleParameterAnnotations 和 RuntimeInvisibleParameterAnnotations,用来描述方法参数的结构, 结构如下图所示:
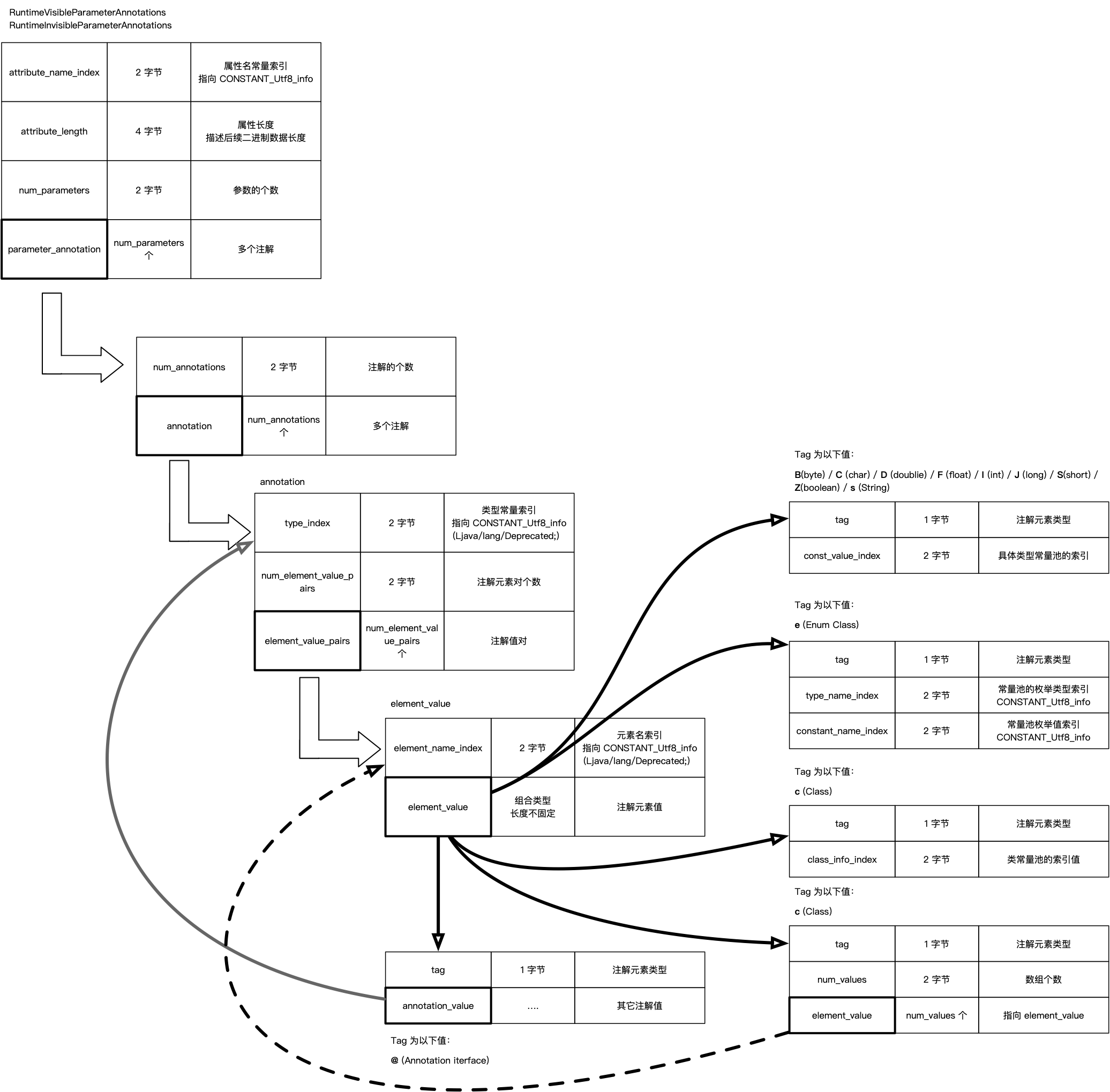
可以看到,在最上层,会有一个多参数的数组结构,而每一个参数对应的注解信息与前面的 RuntimeVisibleAnnotations 的逻辑一致。在代码中添加如下方法:
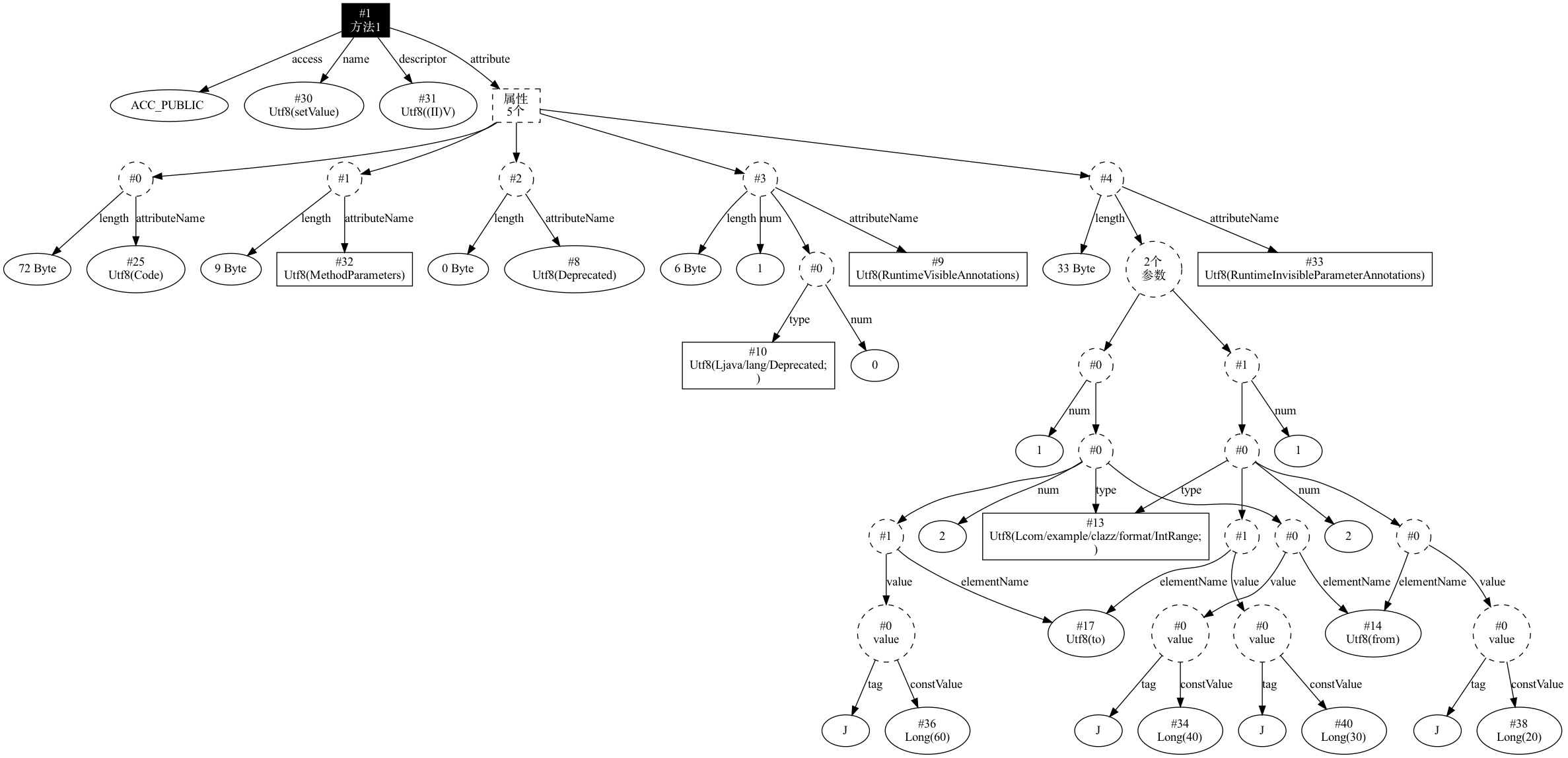
@Deprecated
public void setValue(@IntRange(from = 40, to = 60) int value, @IntRange(from = 20, to = 30) int other) {
this.value = value;
}
最终编译生成的 Class 文件中,方法体中关于注解生成的结构图如下所示:
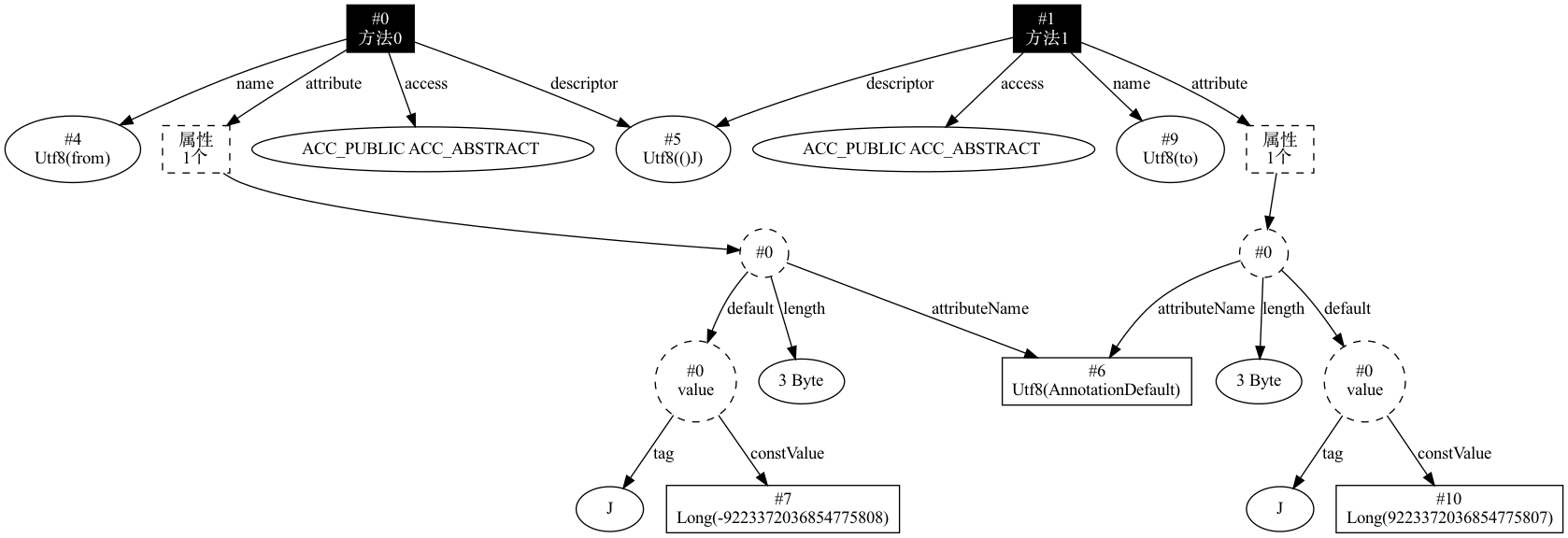
15. AnnotationDefault
在自定义注解时,某些注解元素会存在默认值,在使用的时候不进行设置就可以直接使用,如下代码中的注解定义:
@Retention(CLASS)
@Target({METHOD, PARAMETER, FIELD, LOCAL_VARIABLE, ANNOTATION_TYPE, TYPE})
public @interface IntRange {
/**
* Smallest value, inclusive
*/
long from() default Long.MIN_VALUE;
/**
* Largest value, inclusive
*/
long to() default Long.MAX_VALUE;
}
在这段代码中, from 指定默认值为 Long.MIN_VALUE,to 指定默认值为 Long.MAX_VALUE 。
根据《Java虚拟机规范》中的定义,注解中的元素默认值会被存储在名为 AnnotationDefault 的注解属性中,上述代码最终生成的结构如下所示:
16. TypeAnnotations
在 JDK 8 的版本中,进一步加强了 Java 语言的注解使用范围,添加 TYPE_USE 和 TYPE_PARAMETER 两个注解,在之前,Java 中的注解只能用于类、方法、变量等成员上,而不能用于泛型类型上。加入这两个注解,使得注解可以用于更加丰富的场景中。与其它注解类似,它也分为运行时可见与运行时不可见,即 RuntimeVisibleTypeAnnotations 和 RuntimeInvisibleTypeAnnotations 两个属性。其结构与 RuntimeVisibleAnnotations 略有区别,下图为其结构:
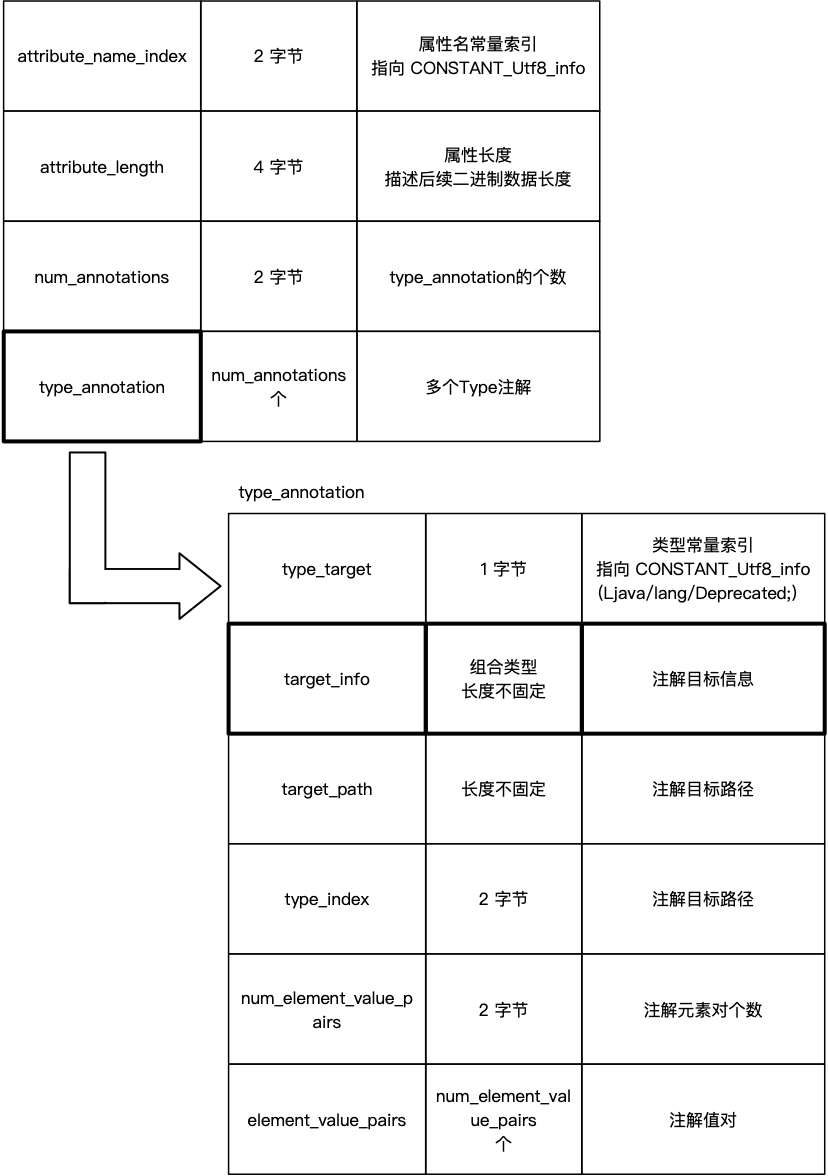
图中加粗的 target_info 也是一个符合类型,有兴趣的同学可以参考《Java 虚拟机规范》。下面列举一个例子,其中 A、B、C、D 四个注解除名称外都一样,具体代码如下:
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE_USE})
@interface A {
}
// 此处省略 B 、C 、D 的代码
public @A Map<@B ? extends @C String, @D List<@E Object>> verbose;
最后,生成出来的结构图如下所示:

17. NestHost 和 NestMembers
NestHost 和 NestMembers 是 Java 11 引入的新特性,用于支持嵌套类的访问控制。在 Java 11 之前,判断一个类是否为嵌套类主要通过查看其访问修饰符和包名来确定。这些属性的引入使得 JVM 能够更好地进行嵌套类的访问控制,从而提高了代码的安全性和性能。先来看一下段示例代码:
public class InnerClassExample {
public class InnerClassDemo {
}
}
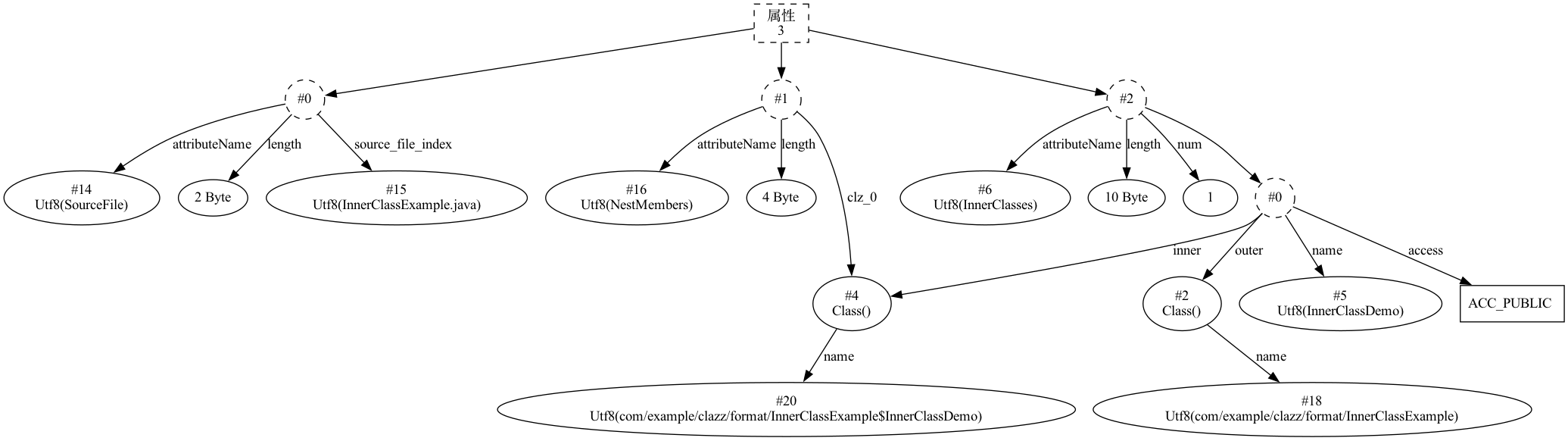
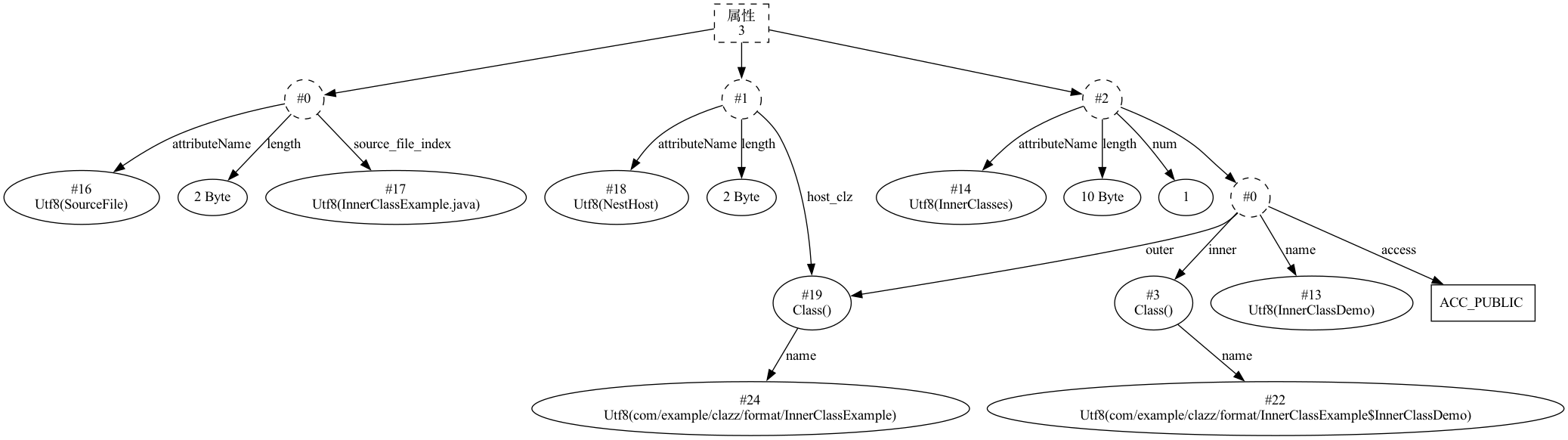
上述代码编译后,会产生两个 Class 文件,它们的名称分别为 InnerClassExample.class 和 InnerClassExample$InnerClassDemo.class。其中NestHost 属性会出现在 InnerClassExample$InnerClassDemo.class 的属性列表中,用于标识所属的封装类,即此处的 InnerClassExample,它是一个可选属性。而 NestMembers 属性会出现在 InnerClassExample.class 的属性列表中,用于标识一个所有嵌套类的列表,此处示例中仅一个嵌套类,所以将只会有一个值 InnerClassExample$InnerClassDemo,它也是一个可选属性。它们的结构也相对简单,如下表所示,
NestHost:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引, 指向常量池中 Utf8 的常量,其值为 NestHost |
| attribute_length | 4 字节 | 常量属性的长度, 此处固定为 0x00000010 |
| host_class_index | 2 字节 | 指向类属性常量值 |
NestMembers:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引, 指向常量池中 Utf8 的常量,其值为 NestHost |
| attribute_length | 4 字节 | 常量属性的长度 |
| number_of_classes | 2 字节 | 嵌套类个数 |
| classes | 2 * number_of_classes 字节 | 指向类属性常量值 |
将示例中的代码编译后生成如下结构:
18. Record
使用String、Integer等类型的时候,这些类型都是不变类,一个不变类具有以下特点:
- 定义class时使用
final,无法派生子类; - 每个字段使用
final,保证创建实例后无法修改任何字段。
假设我们有一个 Person 类,有 name 、age 和 hometown 三个字段 ,如果要把他变成一个不变类,代码会这么写:
public final class Person {
private final String name;
private final int age;
private final String hometown;
public Person(String name, int age, String hometown) {
this.name = name;
this.age = age;
this.hometown = hometown;
}
public String name() {
return this.name;
}
//... 省略部分代码
}
代码写起来还比较多,从 Java 14 开始,引入了一种新的数据类型,Record 类。定义类的时候,使用 record 关键字即可,代码如下:
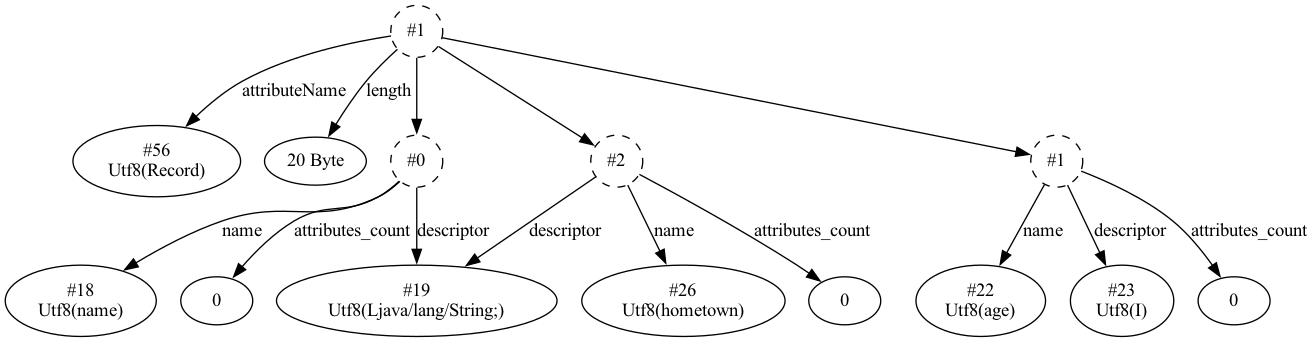
public record Person(String name, int age, String hometown) {
}
此类与前面手写的那个类一样,字段都会标记成 final ,编译器还自动为我们创建了构造方法,和字段名同名的方法,以及覆写toString()、equals()和hashCode()方法。使用一行代码就实现了一个不变类。
此类编译会生成 Record 属性,结构如下:
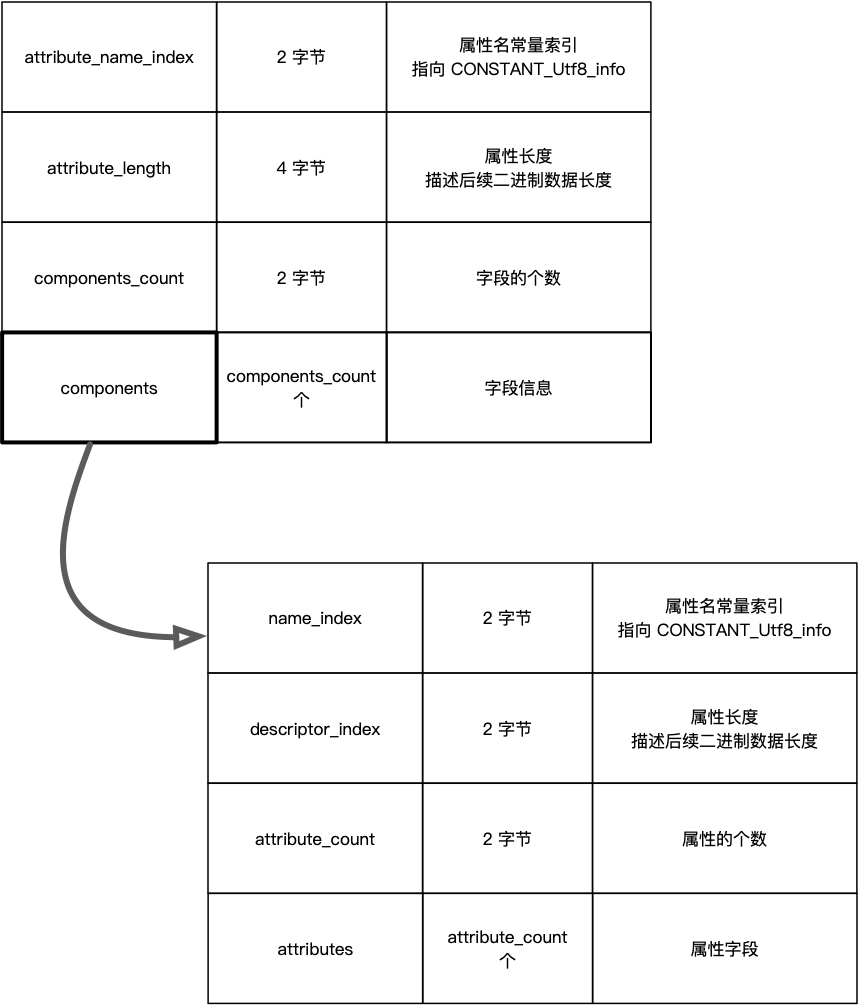
上面的示例代码,编译后,生成的属性 Record 的结构如下图所示:
19. MethodParameters
MethodParameters 是在 JDK 8 时新加入到 Class 文件格式中的,字段是放到方法块中的属性字段里面,是一个变长属性。MethodParameters 的作用是记录方法的各个形参名称和信息。
在虚拟机中,执行代码时,给参数用什么名字对计算机来说没有任何区别。因此在 JDK 8 之前,基于存储空间考虑,Class 文件中默认并不存储任何方法参数名称。但没有名字就会引起如下问题:
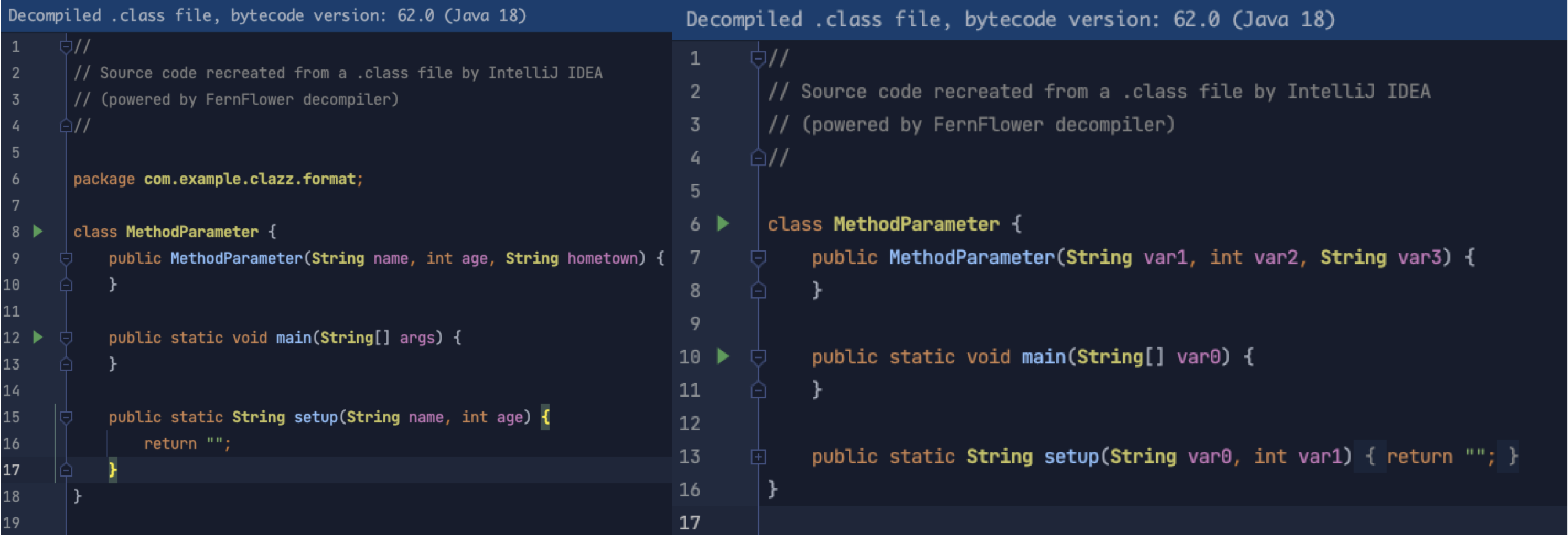
上图中右边部分是不带参数的反编译结果,方法中的参数全部变成了 var1、var2 中这种无用的字段,那别人在调用的时候,就必须得通过 JavaDoc 才能知道每一个参数的含义,使用起来很不方便。
在我本地 IDE 编译时,默认输出的代码依然是不带 MethodParameters 属性的。在编译时需要添加 -parameters 参数,示例命令如下:
javac -parameters MethodParameter.java
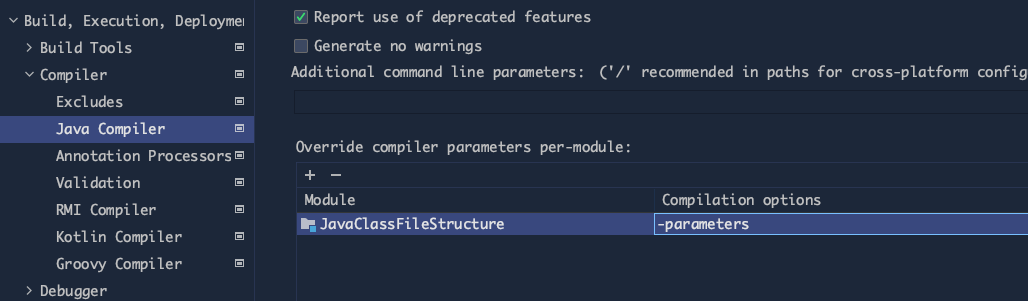
当然,在 IntelliJ IDEA 中也可以添加对应参数,如下图所示:
通过上述设置,编译出来的代码可以生成 MethodParameters 参数了。在来看一下它的结构:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 字节 | 属性名常量索引, 指向值为 MethodParameters |
| attribute_length | 4 字节 | 常量属性的长度 |
| parameters_count | 1 字节 | 参数个数 |
| parameters | parameters_count * 4 字节 | 参数字段信息,见下表 |
其中 parameters 是一个数组,里面可能会包含有多个参数,每一个参数中包含有其名字的信息和访问标识,结构如下图所示:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| name_index | 2 字节 | 参数名称索引, 可能为0,非0时指向常量池中字段名字 |
| access_flags | 2 字节 | 访问标识,ACC_FINAL、ACC_SYNTHETIC、ACC_MANDATED |
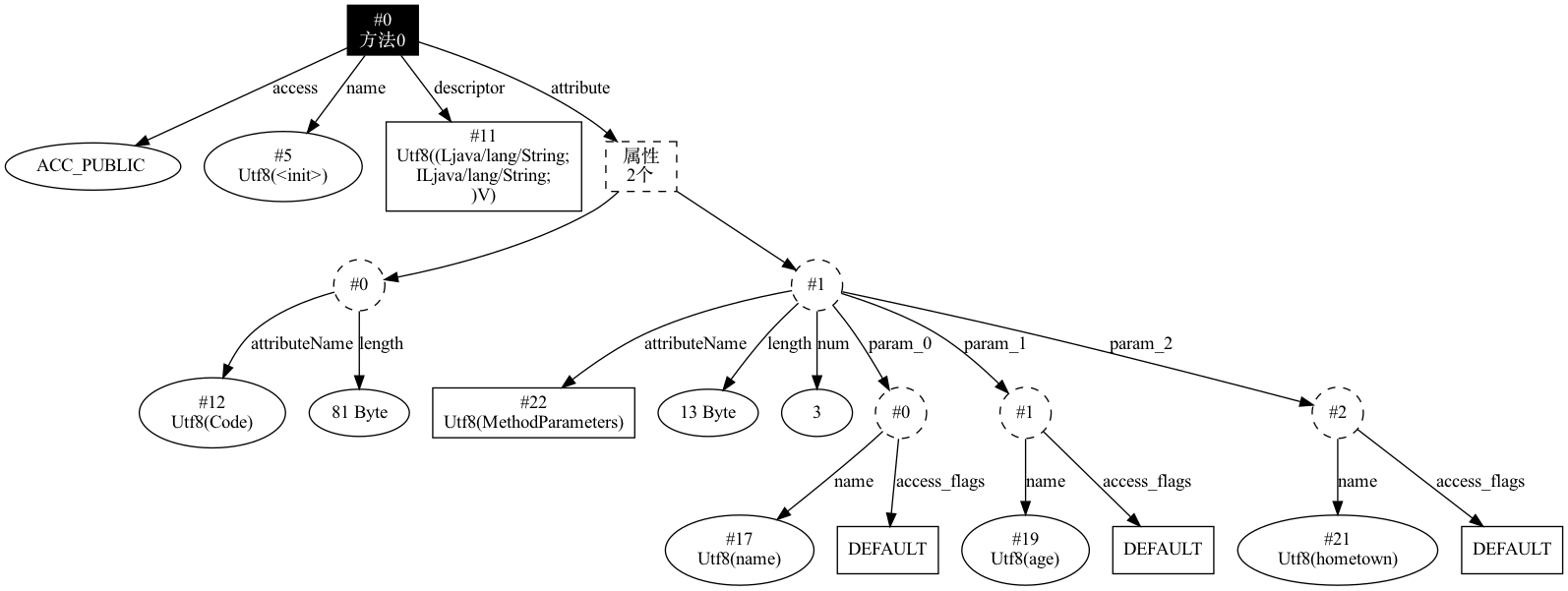
针对刚提到的代码 public MethodParameter(String name, int age, String hometown) {} 生成后的结构如下所示:
20. BootstrapMethods
BootstrapMethods 属性是在 JDK 7 时增加的,用于保存 invokedynamic 指令引用的引导方法限定符。在 《Java虚拟机规范》 中规定,如果常量池中出现 CONSTANT_InvokeDynamic_info 类型的常量时,那么类文件的属性中必须存在 BootstrapMethod 属性。BootstrapMethod 结构如下:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| attribute_name_index | 2 个字节 | 属性名常量池索引,指向值为 BootstrapMethods |
| attribute_length | 4 个字节 | 属性长度 |
| num_bootstrap_methods | 2 个字节 | 引导方法数量 |
| bootstrap_methods | num_bootstrap_methods * 2字节 | 引导方法数组 |
其中,num_bootstrap_methods 表示该属性中引导方法的数量,bootstrap_methods 数组中包含了所有的引导方法。每个引导方法都包含一个引导方法引用和一组引导方法参数。引导方法的结构如下:
| 字段名 | 数据长度 | 描述 |
|---|---|---|
| bootstrap_method_ref | 2 字节 | 对常量池中的 CONSTANT_MethodHandle_info 或 CONSTANT_MethodType_info 常量的引用 |
| num_bootstrap_arguments | 2 字节 | 引导方法的参数数量 |
| bootstrap_arguments | 2 * num_bootstrap_arguments 字节 | 引导方法的参数列表,每个元素都是对常量池中的一个常量的引用 |
其中,bootstrap_method_ref 是对常量池中的 CONSTANT_MethodHandle_info 或 CONSTANT_MethodType_info 常量的引用。num_bootstrap_arguments 是引导方法的参数数量,bootstrap_arguments 是引导方法的参数列表,每个元素都是对常量池中的一个常量的引用。
下面是我写的一段代码,用来查看 BootstrapMethods 的最终结构:
public void print() {
Runnable r = () -> System.out.println("Hello world");
r.run();
}
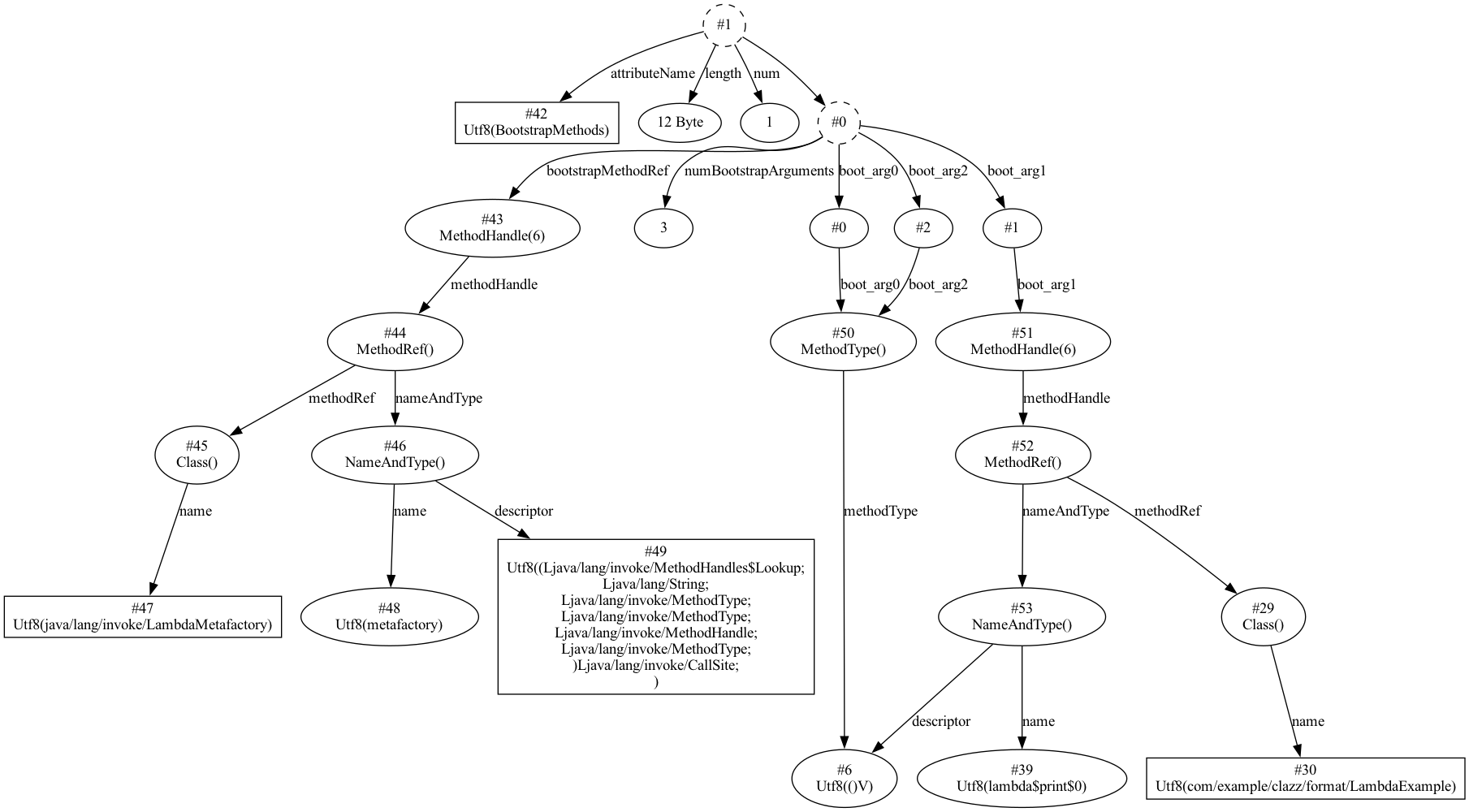
最终生成的结构图如下:
21. 模块化相关属性
JDK 9 发布了一个非常重要的功能,那就是 Java 的模块化,模块化描述文件 module-info.java 最终也会编译成独立的 Class 文件来存储,Class 文件属性中扩展了 Module 、ModulePackages 和 ModuleMainClass 三个属性用于支持 Java 模块化的相关功能。其属性结构也相对较复杂,但模块化功能在开发中基本没有使用过,在此也不过多赘述,其结构信息,如你感兴趣,可以去查阅 《Java 虚拟机规范》。
22. PermittedSubclasses
在 Java 17 正式发布了 Sealed Classes, 翻译为密封类、封闭类。代表该类/接口是一个封闭的类/接口,只有许可的类/接口才能继承或实现该类/接口。如果是 sealed 修饰的类,就会有 PermittedSubclasses 属性。
在没有封闭类之前,Java 控制类继承有两种方式:
- 用关键字
final修饰类,类就成了终态类,无法被继承;比如我们经常使用的String类 package-private的类, 即非public类,这样只有同包下的类才能继承
针对package-private 的类, 还是能被继承后并进行扩展,而封闭类能够提供了更精细粒度的可扩展性。 PermittedSubclasses 属性就是用来记录这些信息的:
| 字段名 | 数据长度 | 说明 |
|---|---|---|
| attribute_name_index | 2 个字节 | 属性名索引 |
| attribute_length | 4 个字节 | 属性长度 |
| number_of_classes | 2 个字节 | 允许的子类数量 |
| classes | number_of_classes * 2 字节 | 子类集合 |
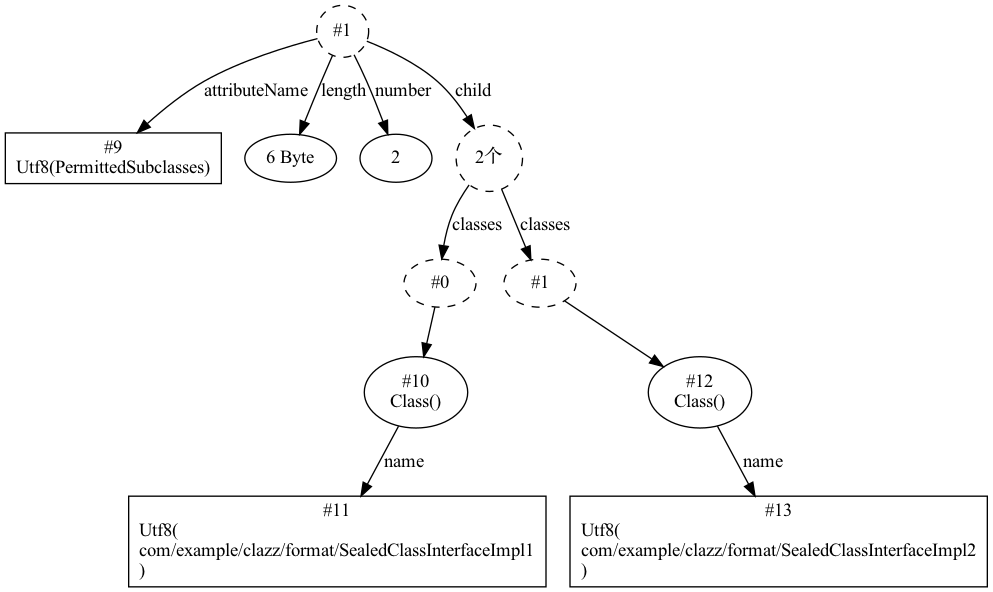
其中,number_of_classes 表示该类允许被继承的类的个数,classes 数组中包含了所有的指定的继承类,里面存储的为常量池指针,指向的为 CONSTANT_Class_info 字段。
下面是我写的一段代码,用来查看 PermittedSubclasses 的最终结构:
public sealed interface SealedClassInterface
permits SealedClassInterfaceImpl1, SealedClassInterfaceImpl2 {
}
最终生成的结构图如下: