Git 必知必会:原理剖析(二)
书接上文,在上一篇文章记录Git 必知必会:原理解析 中记录了 Git 原理中的一部分信息,但在后续的学习过程中,还有部分内容需要记录,但有了此篇内容。
一、Git 中的引用
从上面的 Git 仓库树目录存储结构图中,可以看到,通过 commit 的 SHA-1 值,我们就一步一步查看所有的提交记录,以及项目中的文件内容。但 40 位的字符串几乎不可能记忆下来,也没有什么实质性的意义。那如果我们能给这些值取上一个别名,那是不是就能够很容易找到以及使用了。
在 Git 中,此功能是使用引用文件来实现的,在 .git/refs 文件下就可以找到此类引用文件。文件名就是别名,而文件内容中存储的就是对应的 SHA-1 值。在使用的时候,直接使用这个别名就可以了。
HEAD 引用
当在工作目录中执行一些 Git 相关命令的时候,Git 是如何知道当前最新提交的 SHA-1 值呢? 这一切的答案就在 HEAD 文件中,此文件中存储的数据指向了当前分支,在我的示例中:
$ cat .git/HEAD
ref: refs/heads/main
HEAD 文件中指向的是 .git/refs/heads/main 这个文件,此文件中存储了 602ac5 的 SHA-1 值。
当我们在执行切换分支的时候, HEAD 文件就会被更改掉,指向的为你切换过去的分支。
$ git checkout -b test
Switched to a new branch 'test'
$ cat .git/HEAD
ref: refs/heads/test
因此,Git 在使用的时候,通过 HEAD 中指向的 refs 文件,找到当前所在的最新 commit 的 SHA-1 值,并进行相关操作。
分支引用
也许你已经从刚的示例中发现,本地的分支对应的引用文件都是在 refs/heads 目录下。那远程分支呢? 本地分支是如何与远程分支关联的呢?
在 Git 中,有三种分支类型: 本地分支、本地远程分支、远程分支。其中 本地远程分支 可以理解为 远程分支 的一个镜像,在 clone 或者对已有项目执行 fetch 时,会将 远程分支 中的信息同步到 本地远程分支 中。按照 Git Refs 的规范,默认情况下,远程分支都会放到 .git/refs/remotes/origin 下面。在我们使用git remoted add origin <git url> 时,默认会在 .git/config 中制定相应配置:
[remote "origin"]
url = <git url>
fetch = +refs/heads/*:refs/remotes/origin/*
在 fetch 的那一行中,由一个可选的 + 和紧随其后的 <src>:<dst> 组成。其中 + 指在不能 fast forwad 的时候,也要强制更新引用;<src> 指的是远程版本库中的引用,可使用通配符进行匹配;<dst>指的是本地跟踪的远程引用的位置。 所以,在本地项目中,会将远程分支的镜像存储到 refs/remotes/origin 下面,并且与远程分支一一对应。
而我们在本地使用的时候,操作的是本地分支,大多数情况,本地分支都是需要和远程分支进行关联的。具体关联配置也是在 .git/config 这个文件中,可以通过命令 get branch -vv 查看关联关系。在配置文件中,也包含了其关联关系,内容如下:
[branch "main"]
remote = origin
merge = refs/heads/main
[branch "test"]
remote = origin
merge = refs/heads/test
TAG 引用
在 Git 中,还有一个非常常用的功能,TAG 分为两种,一种是轻量标签, 一种是带备注的标签。
轻量标签:
仅包含一个轻量标签一个固定的引用,此固定引用只想了项目中的某一个 commit 的 SHA-1 值。在本地可以直接使用 git tag <tag_name> 创建,此时会在 refs/tags 下面创建 <tag_name> 命名的文件。
附注标签:
在创建标签时,也可以给标签附加一些信息,用于描述标签的细节信息。使用时,可以用如下命令进行创建:
git tag -a <tag_name> -m "message"
与轻量标签不同的是,这条命令会创建一个 Git 对象,放到 refs/objects 中,在 refs/tags 目录中对应的文件中,记录的便是这个 tag 对象的 SHA-1 值。
与 Commit 类似,tag 的对象中的内容也是按固定格式处理,具体格式内容如下:
tag <content length><NUL>object <object SHA-1>
type commit
tag <tag name>
tagger <username> <email> <timestamp>
<tag comment message>
最后,在来看一下,我本地创建的两个不同的 Tag,如下图所示: 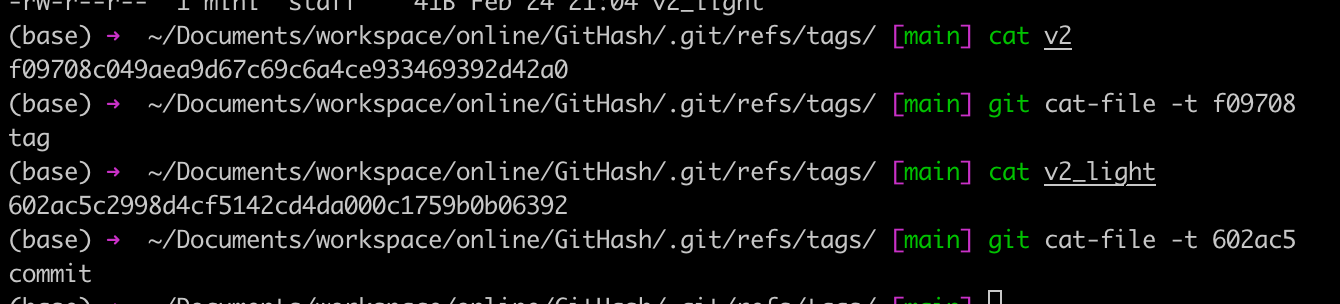
二、Git 文件打包
在我们写代码的时候,某些原文件会出现频繁的更改,从前面 blob 创建过程,我们知道,每一个版本的文件都会重新创建。为了更好的理解这个过程,创建一个 Git 项目,里面仅放了一个简单的 txt 文件:
- 我使用了本文的第一版内容,使用命令将此文件添加到 Git 后,会生成第一个 blob :
7e/5968ece2093c89df8e63ff6e72fff759cc5b74,此时,此文件大约 7.8KB。 - 经过简单的修改,在次添加到 git 中,会生成新的 blob:
f7/eed43792fe8d9b016e8f8a8085b1949075d299, 此文件大小也差不多 7.8KB。
通过上面的步骤,在磁盘中,相当于保存了两个几乎完全相同的文件。如果 Git 只完整保存其中一个,在保存另一个 blob 与之前版本的差异内容,岂不是更好?
事实上,Git 的做法与我们的想法一致。Git 在最初往磁盘中存储对象时,使用的格式被称为“松散”对象格式。但是为了更加高效的管理文件,Git 会时不时将这些对象打包在一起形成为一个新二进制文件。当然,我们可以通过 git gc 命令来触发,如下所示:
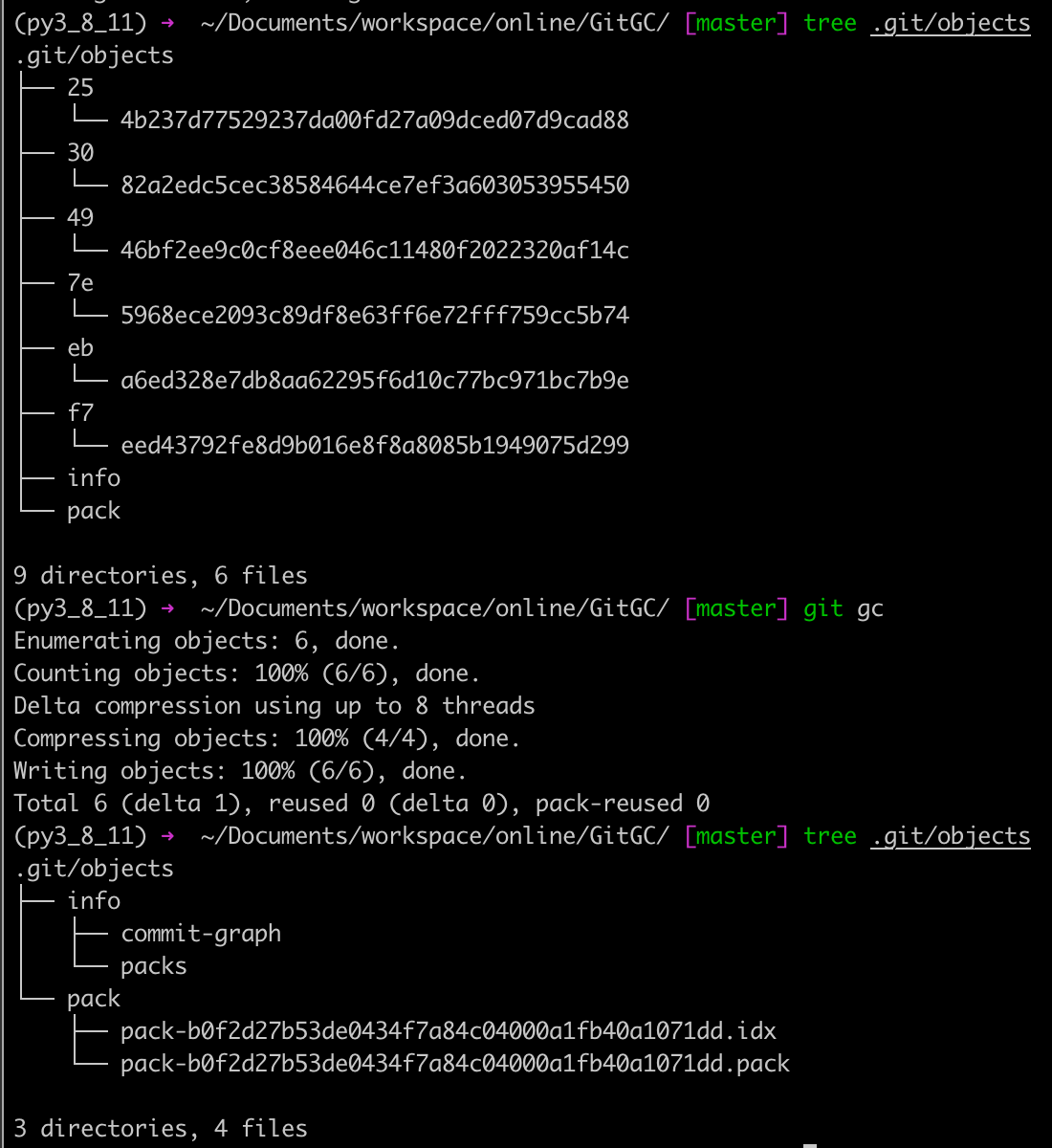
经过打包后的文件大小也会变小:

三、Git LFS 协议
此部分主要内容来源于官方文档: https://github.com/git-lfs/git-lfs/blob/main/docs/api/batch.md
Git LFS 有不同的语言实现的不同版本, 只要遵循 LFS 协议就可以了。从文档中我们可以看到, 当在执行 Git LFS 命令时,会先发送一个 Batch API,此接口需要使用 POST 方式进行网络请求发送,URL 地址为: https://<git_url>/info/lfs/objects/batch,其中 http headers 必须包含如下内容:
Accept: application/vnd.git-lfs+json
Content-Type: application/vnd.git-lfs+json; charset=utf-8
而在 request body 里面,使用 JSON 进行编码,内容中包含如下信息:
- operation: 这个值只能为 download 或者 upload
- transfers: 可选,客户端配置的、支持的传输协议,与服务端协商后续大文件传输到 CDN 使用协议方式
- ref: 可选, 标识当前对象在服务端的哪个分支
- objects: 要进行上传或者下载的对象数组,包含有
oid和size两个信息 - hash_algo: Git LFS 在本地计算大文件使用的 hash 算法,默认为 sha256
而 response 的内容中,也会将 Git LFS 需要的信息下发下来,会将 request 中的 objects 的 CDN 地址,以及访问需要的 token 等信息进行下发,用于后续的请求,下面来看一下我对 LFS 下载数据抓包的过程:
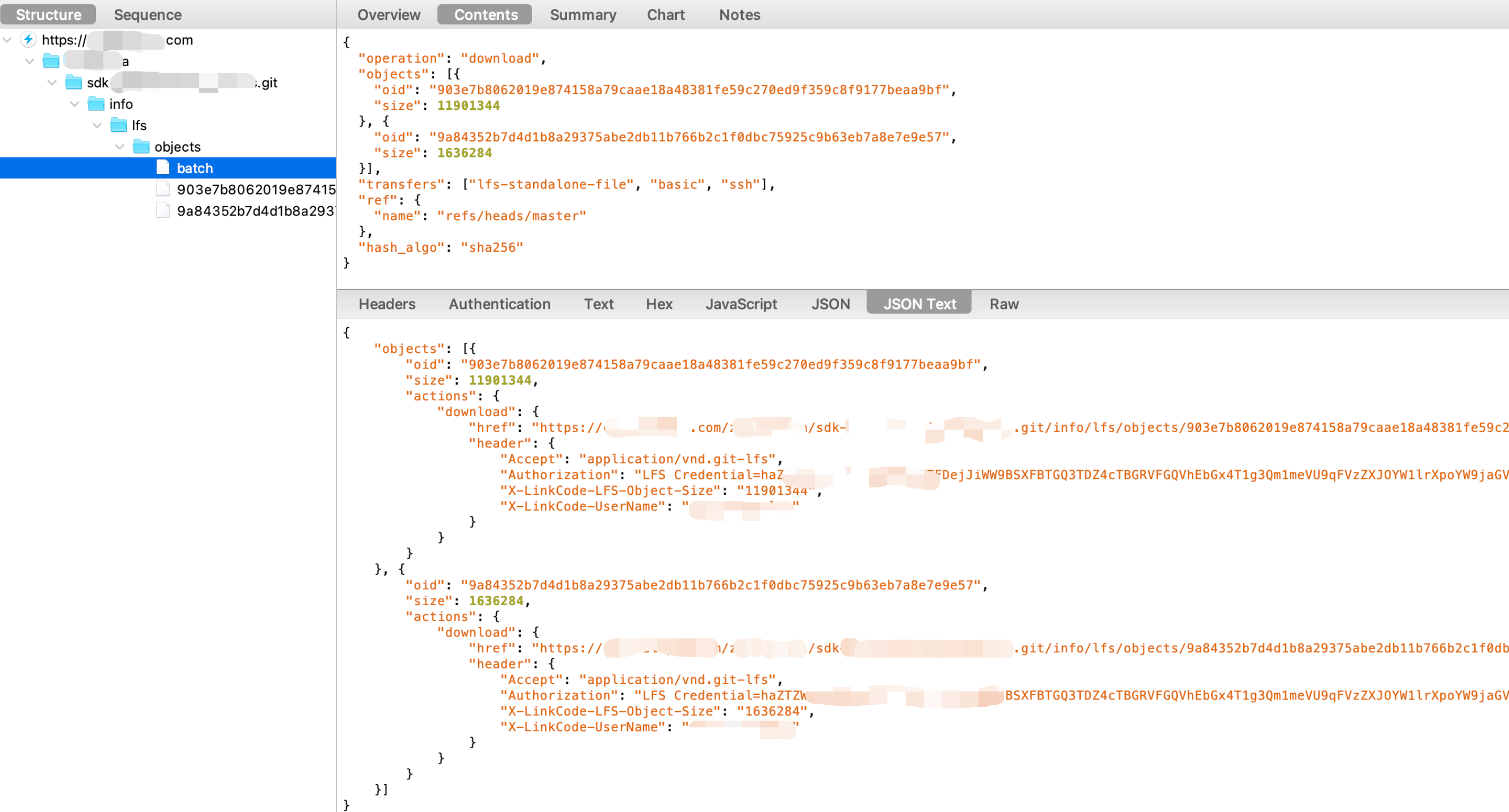
更多细节信息,请参考官方文档。